AWS Certified Solutions Architect - Professional Road Map
Official AWS Certification Page
- 参加 AWS 培训课程
- 查看考试指南和样题
- 了解考试涉及的概念并整体了解需要学习哪些内容, AWS Certified Solutions Architect – Professional 考试指南 相当于考试大纲, 必看,而且需要反复的看。因为学习过一阵后再来看Guide,会有更深的体会。
- 考试样题用于熟悉题目题型。几个样题都是大段大段的文字,实际考试题目中也有字数少的题目。但题目的阅读量绝对是比Asoocaiated的大得多。
- 练习试验
- 注册一个AWS全球账号,使用一年的免费额度结合Blueprint中的各个内容进行试验。
- 学习 AWS 白皮书
- 白皮书是纯英文的,每个白皮书篇幅都很长。
- 在BluePrint的描述中,和AWS Certified Solutions Architect - Associate的白皮书列表相比,多了Defining Fault Tolerant Applications in the AWS Cloud这一份白皮书,官网找了一下,只有一个名字类似的名为Building Fault-Tolerant Applications on AWS的白皮书,时间还是October 2011的。不管怎样,但愿好理念永不过时,还是整个念一遍吧。
- 查看 AWS 常见问题
- 官网推荐的FAQ都建议看完。
- 参加模拟考试
- 40美刀一次。是否值得因人而异。参加Professional的考试,肯定都已经经历过AWS Certified Solutions Architect – Associate的洗礼了, 因此熟悉考试界面肯定不是决定要参加模拟考试的目的。一个合理的理由是,可以提前熟悉一下Professional考题阅读难度, 为正式考试的时候做好心理准备。网上都说AWS Certified Solutions Architect – Professional这个考试最大的难度就是要在170分钟内阅读,理解77~80道字数不算少的题,然后选出最优的答案。网上一些母语是英语的老外都感慨阅读量比较大,何况是我们这种非英语系的国家的考生了。
- 报名考试并获得认证
考试指南
AWS Certified Solutions Architect – Professional 考试指南 读三遍,读三遍,读三遍
总计8个Domain, 各个Domain占的百分比如下
- High Availability and Business Continuity - 15%
- Costing - 5%
- Deployment Management - 10%
- Network Design - 10%
- Data Storage - 15%
- Security - 20%
- Scalability & Elasticity - 15%
- Cloud Migration & Hybrid Architecture - 10%
涉及到的AWS Services
- AWS KMS
- AWS Import/Export
- AWS STS
- CloudFormation
- CloudFront
- CloudHSM
- CloudSearch
- CloudWatch
- CloudTrail
- Data Pipeline
- Direct Connect
- DynamoDB
- EBS
- EC2
- AutoScaling
- ELB
- EMR
- ElastiCache
- Elastic Beanstalk
- Elastic Transcoder
- Glacier
- IAM
- Kinesis
- OpsWorks
- RDS
- RedShift
- Route 53
- S3
- SES
- SNS
- SQS
- SWF
- Storage Gateway
- VPC
视频学习
网上有多种视频教程,当时个人觉得Acloudguru的AWS Associated系列的教程非常好(三份Associated的教程都买了),因此此次也购买了Acloudguru的AWS Certified Solutions Architect – Professional的教程。但学下来整体感觉这个Professional的教程一般,总感觉内容和AWS Certified Solutions Architect – Associated系列的差不多。不够深入和细致。其余的教程没有学习过,因此无法做评价。
要点摘录
Domain 1 - High Availability and Business Continuity - 15%
Disaster Recovery
- WhitePaper : https://media.amazonwebservices.com/AWS_Disaster_Recovery.pdf
- What is Disaster Recovery
- Disaster recovery (DR) is about preparing for and recovering from a disaster. Any event that has a negative impact on a company’s business continuity or finances could be termed a disaster. This includes hardware or software failure, a network outage, a power outage, physical damage to a building like fire or flooding, human error, or some other significant event.
- Recovery Time Objective (RTO)
- Recovery Time Objective is the amount of time that it takes for your business to recover from an outage or disruption.
- It can include the time for trying to fix the problem without a recovery, the recovery itself, testing and the communication to the users
- Recovery Point Objective (RPO)
- Recovery Point Objective (RPO) is the maximum period of time in which data might be lost from an IT service due to a major incident.
- In other words, how much data can your organization afford to lose? An hour’s worth? A day’s worth? None at all?
- Traditional Approaches to DR
- A traditional approach to DR usually involves an N+1 approach and has different levels of off-site duplication of data and infrastructure.
- Facilities to house the infrastructure, including power and cooling
- Security to ensure the physical protection of assets
- Suitable capacity to scale the environment
- Support for repairing, replacing, and refreshing the infrastructure
- Contractual agreements with an Internet service provider (ISP) to provide Internet connectivity that can sustain bandwidth utilization for the environment under a full load
- Network infrastructure such as firewalls, routers, switches, and load balancers
- Enough server capacity to run all mission-critical services, including storage appliances for the supporting data, and servers to run applications and backend services such as user authentication, Domain Name System (DNS)
- Dynamic Host Configuration Protocol (DHCP), monitoring, and alerting
- A traditional approach to DR usually involves an N+1 approach and has different levels of off-site duplication of data and infrastructure.
- Why use aws for DR
- Only minimum hardware is required for ‘data replication’
- Allows you to be flexible depending on what your disaster is and how to recover from it
- Open cost model (pay as you use) rather than heavy investment upfront. Scaling is quick and easy
- Automate disaster recovery deployment
- What Services
- Regions
- Storage
- S3 - 99.999999999% durability and Cross Region Replication
- Glacier
- Elastic Block Store (EBS)
- Direct Connect
- AWS Storage Gateway
- Gateway-cached volumes - store primary data and cache most recently used data locally.
- Gateway-stored volumes - store entire dataset on site and asynchronously replicate data back to S3
- Gateway-virtual tape library - Store your virtual tapes in either S3 or Glacier
- Compute
- EC2
- EC2 VM Import Connector - Virtual appliance which allows you to import virtual machine images from your existing environment to Amazon EC2 instances.
- Networking
- Route53
- Elastic Load Balancing
- Amazon Virtual Private Cloud (VPC)
- Amazon Direct Connect
- Database
- RDS
- DynamoDB
- Redshift
- Orchestration
- CloudFormation
- ElasticBeanstalk
- OpsWork
- Lambda
- DR Scenarios
- Four Scenarios
- Backup & Restore
- Pilot Light
- Warm Standby
- Multi Site
- Backup & Restore
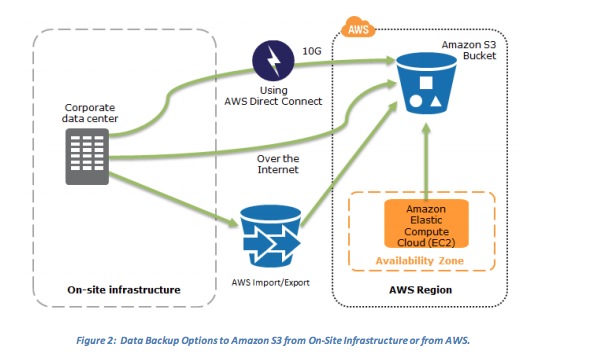
- In most traditional environments, data is backed up to tape and sent off-site regularly. If you use this method, it can take a long time to restore your system in the event of a disruption or disaster. Amazon S3 is an ideal destination for backup data that might be needed quickly to perform a restore. Transferring data to and from Amazon S3 is typically done through the network, and is therefore accessible from any location.
- You can use AWS Import/Export to transfer very large data sets by shipping storage devices directly to AWS. For longer-term data storage where retrieval times of several hours are adequate, there is Amazon Glacier, which has the same durability model as Amazon S3. . Amazon Glacier and Amazon S3 can be used in conjunction to produce a tiered backup solution.
- Data Backup Options to Amazon S3 from On-Site Infrastructure or from AWS.
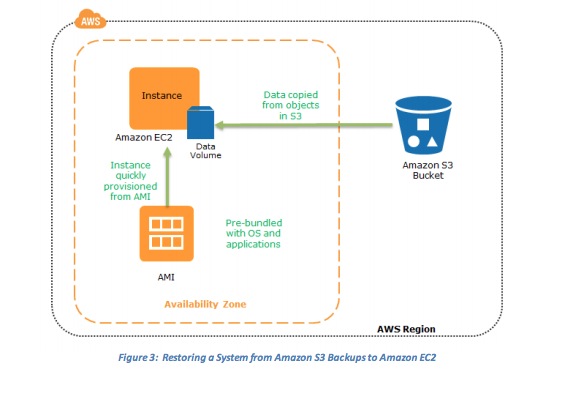
- Restoring a System from Amazon S3 Backups to Amazon EC2
- Key steps for backup & restore
- Select an appropriate tool or method to back up your data into AWS.
- Ensure that you have an appropriate retention policy for this data.
- Ensure that appropriate security measures are in place for this data, including encryption and access policies.
- Regularly test the recovery of this data and the restoration of your system.
- Pilot Light
- The term pilot light is often used to describe a DR scenario in which a minimal version of an environment is always running in the cloud. The idea of the pilot light is an analogy that comes from the gas heater. In a gas heater, a small flame that’s always on can quickly ignite the entire furnace to heat up a house.
- This scenario is similar to a backup-and-restore scenario. For example, with AWS you can maintain a pilot light by configuring and running the most critical core elements of your system in AWS. When the time comes for recovery, you can rapidly provision a full-scale production environment around the critical core.
- Infrastructure elements for the pilot light itself typically include your database servers, which would replicate data to Amazon EC2 or Amazon RDS. Depending on the system, there might be other critical data outside of the database that needs to be replicated to AWS. This is the critical core of the system (the pilot light) around which all other infrastructure pieces in AWS (the rest of the furnace) can quickly be provisioned to restore the complete system.
- To provision the remainder of the infrastructure to restore business-critical services, you would typically have some preconfigured servers bundled as Amazon Machine Images (AMIs), which are ready to be started up at a moment’s notice. When starting recovery, instances from these AMIs come up quickly with their pre-defined role (for example, Web or App Server) within the deployment around the pilot light.
- From a networking point of view, you have two main options for provisioning:
- Use pre-allocated elastic IP address and associate them with your instances when invoking DR. You can also use pre-allocated elastic network interfaces (ENIs) with pre-allocated Mac Addresses for applications with special licensing requirements
- Use Elastic Load Balancing (ELB) to distribute traffic to multiple instances. You would then update your DNS records to point at your Amazon EC2 instance or point to your load balancer using a CNAME
- Preparation phase
- The Preparation Phase of the Pilot Light Scenario
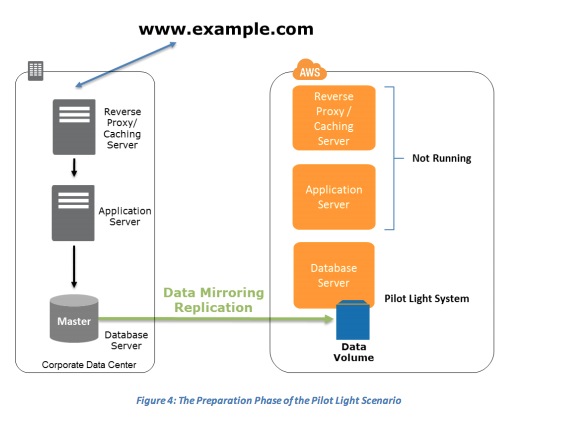
- Key steps for preparation:
- Set up Amazon EC2 instances to replicate or mirror data.
- Ensure that you have all supporting custom software packages available in AWS.
- Create and maintain AMIs of key servers where fast recovery is required.
- Regularly run these servers, test them, and apply any software updates and configuration changes.
- Consider automating the provisioning of AWS resources
- The Preparation Phase of the Pilot Light Scenario
- Recovery phase
- The Recovery Phase of the Pilot Light Scenario
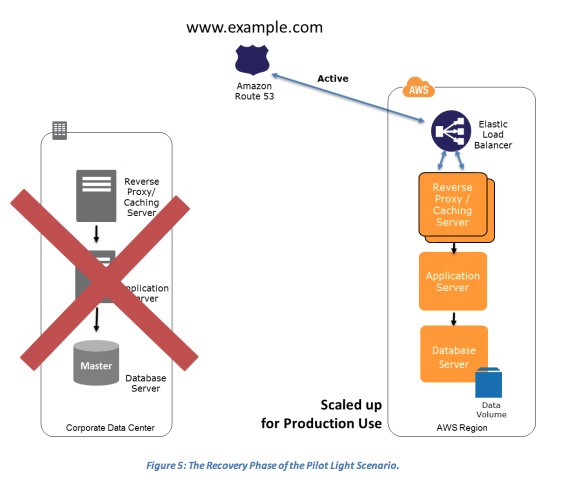
- Key steps for recovery:
- Start your application Amazon EC2 instances from your custom AMIs.
- Resize existing database/data store instances to process the increased traffic.
- Add additional database/data store instances to give the DR site resilience in the data tier; if you are using Amazon RDS, turn on Multi-AZ to improve resilience.
- Change DNS to point at the Amazon EC2 servers.
- Install and configure any non-AMI based systems, ideally in an automated way.
- The Recovery Phase of the Pilot Light Scenario
- Warm Standby
- The term warm standby is used to describe a DR scenario in which a scaled-down version of a fully functional environment is always running in the cloud. A warm standby solution extends the pilot light elements and preparation. It further decreases the recovery time because some services are always running. By identifying your business-critical systems, you can fully duplicate these systems on AWS and have them always on.
- These servers can be running on a minimum-sized fleet of Amazon EC2 instances on the smallest sizes possible. This solution is not scaled to take a full-production load, but it is fully functional. It can be used for non-production work, such as testing, quality assurance, and internal use.
- In a disaster, the system is scaled up quickly to handle the production load. In AWS, this can be done by adding more instances to the load balancer and by resizing the small capacity servers to run on larger Amazon EC2 instance types.
- Horizontal scaling is preferred over vertical scaling
- Preparation phase
- The Preparation Phase of the Warm Standby Scenario
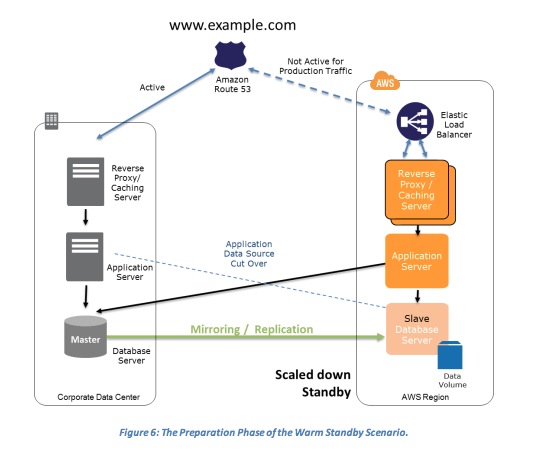
- Key steps for preparation:
- Set up Amazon EC2 instances to replicate or mirror data.
- Create and maintain AMIs.
- Run your application using a minimal footprint of Amazon EC2 instances or AWS infrastructure.
- Patch and update software and configuration files in line with your live environment.
- The Preparation Phase of the Warm Standby Scenario
- Recovery phase
- The Recovery Phase of the Warm Standby Scenario
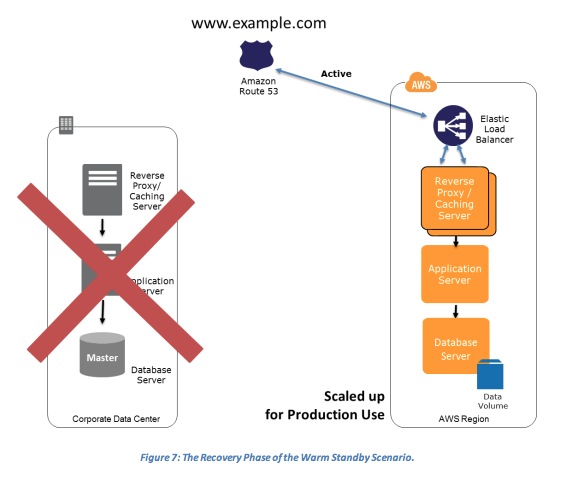
- Key steps for recovery:
- Increase the size of the Amazon EC2 fleets in service with the load balancer (horizontal scaling).
- Start applications on larger Amazon EC2 instance types as needed (vertical scaling).
- Either manually change the DNS records, or use Amazon Route 53 automated health checks so that all traffic is routed to the AWS environment.
- Consider using Auto Scaling to right-size the fleet or accommodate the increased load.
- Add resilience or scale up your database.
- The Recovery Phase of the Warm Standby Scenario
- Multi Site
- A multi-site solution runs in AWS as well as on your existing on-site infrastructure, in an active-active configuration. The data replication method that you employ will be determined by the recovery point that you choose.
- You can use Route53 to root traffic to both sites either symmetrically or asymmetrically.
- In an on-site disaster situation, you can adjust the DNS weighting and send all traffic to the AWS servers. The capacity of the AWS service can be rapidly increased to handle the full production load. You can use Amazon EC2 Auto Scaling to automate this process. You might need some application logic to detect the failure of the primary database services and cut over to the parallel database services running in AWS.
- Preparation phase
- The Preparation Phase of the Multi-Site Scenario
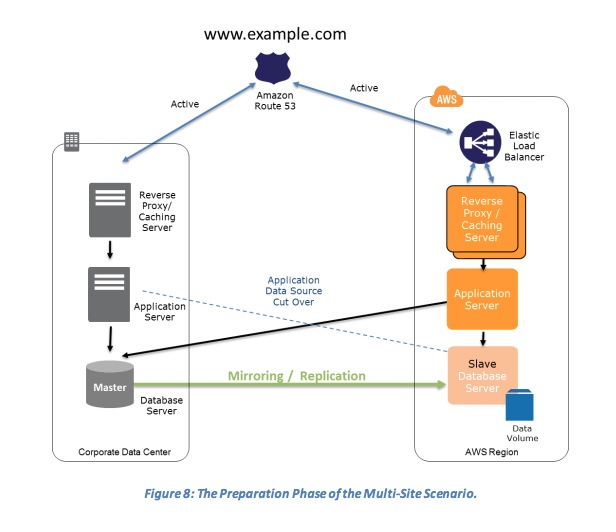
- Key steps for preparation:
- Set up your AWS environment to duplicate your production environment.
- Set up DNS weighting, or similar traffic routing technology, to distribute incoming requests to both sites. Configure automated failover to re-route traffic away from the affected site.
- The Preparation Phase of the Multi-Site Scenario
- Recovery phase
- The Recovery Phase of the Multi-Site Scenario Involving On-Site and AWS Infrastructure.
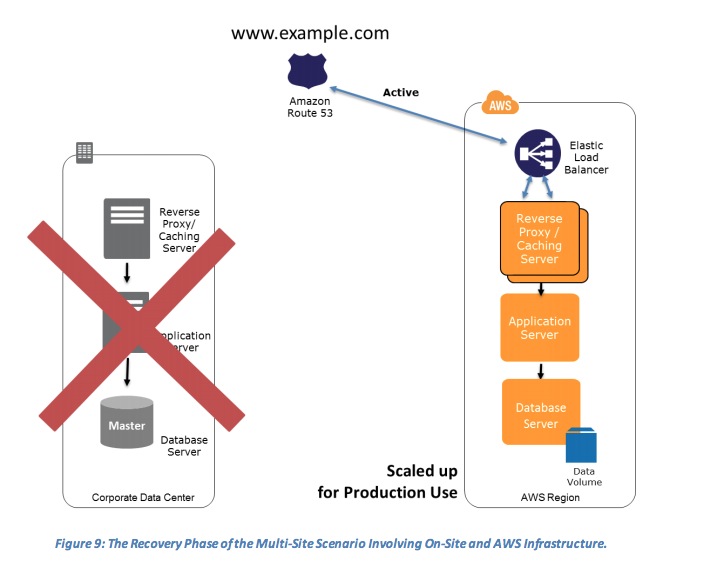
- Key steps for recovery:
- Either manually or by using DNS failover, change the DNS weighting so that all requests are sent to the AWS site.
- Have application logic for failover to use the local AWS database servers for all queries.
- Consider using Auto Scaling to automatically right-size the AWS fleet.
- The Recovery Phase of the Multi-Site Scenario Involving On-Site and AWS Infrastructure.
- Failing Back
- Backup and restore
- Freeze data changes to the DR site
- Take a backup
- Restore the backup to the primary site
- Re-point users to the primary site
- Unfreeze the changes
- Pilot light, warm standby, and multi-site:
- Establish reverse mirroring/replication from the DR site back to the primary site, once the primary site has caught up with the changes.
- Freeze data changes to the DR site
- Re-point users to the primary site
- Unfreeze the changes
- Backup and restore
- Four Scenarios
- Exam Tips
- You will be given different RTO’s and RPO’s and then asked which AWS services you should choose. All choices may be correct, just some are more correct than others.
- Key AWS Back Up & DR Technologies
- S3 provides a highly durable storage infrastructure designed for mission critical and primary data storage. Objects are redundantly stored on multiple devices across multiple facilities within a region, designed to provide a durability of 99.999999999% (11 9s)
- Archives (think objects) are optimized for infrequent access, for which retrieval times of several hours are adequate. It can take at least 3 Hours to recover a file from glacier.
- EBS provides the ability to create point-in-time snapshots of data volumes.
- DynamoDB offers cross region replication. You can read more about how to set it up here.
- RDS gives you the ability to snapshot data from one region to another, and also to have a read replica running in another region.
- Redshift: snapshot your data warehouse to be durably stored in Amazon S3 within the same region or copied to another region.
DR&BC For Database
- HA for Popular Database
- SQL Server = AlwaysOn Availability Groups, SQL Mirroring
- MySQL = Asynchronous replication
- Oracle = Oracle Data Guard, Oracle RAC
- RDS Multi-AZ Failover
- Automatic failover in case of
- Loss of availability in primary AZ
- Loss of connectivity to primary DB
- Storage or host failure to primary DB
- Software patching
- Rebooting of primary DB.
- MultiAZ deployments for Oracle, PostgreSQL, MySQL, and MariaDB DB instances use Amazon’s failover technology.
- SQL Server DB instances use SQL Server Mirroring.
- Amazon Aurora instances stores copies of the data in a DB cluster across multiple Availability Zones in a single region.
- All approaches safeguard your data in the event of a DB instance failure or loss of an Availability Zone.
- Automatic failover in case of
- Read Replica
- What are Read Replica
- Read Replicas make it easy to take advantage of supported engine’s built-in replication functionality to elastically scale out beyond the capacity constraints of a single DB Instance for read-heave database workloads.
- Read only copies of your database.
- You can create a Read Replica with a few clicks in the AWS Management Console or using the CreateDBInstanceReadReplica API. Once the Read Replica is created, database updates on the source DB Instance will be replicated using a supported engine’s native, asynchronous replication. You can create multiple Read Replicas for a given source DB Instance and distribute your application’s read traffic amongst them.
- When would you use read replica’s
- Scaling beyond the compute or I/O capacity of a single DB Instance for read-heavy database workloads. This excess read traffic can be directed to one or more Read Replicas
- Serving read traffic while the source DB Instance is unavailable. If your source DB Instance cannot take I/O requests (e.g. due to I/O suspension for backups or scheduled maintenance), you can direct read traffic to your Read Replica
- Business reporting or data warehousing scenarios; you may want business reporting queries to run against a Read Replica, rather than your primary, production DB Instance.
- Supported Versions
- MySQL
- MySQL 5.6 (NOT 5.1 or 5.5)
- Can use both MySQL engines (MyISAM and InnoDB) however only InnoDB is supported by AWS
- PostgreSQL
- PostgreSQL 9.3.5 or newer
- MariaDB
- All current versions
- For all 3 Amazon uses these engines native asynchronous replication to update the read replica
- Oracle and MSSQL
- All current versions
- Aurora
- Aurora employees an SSD-backed virtualized storage layer purpose-built for database workloads. Amazon Aurora replica share the same underlying storage as the source instance, lowering costs and avoiding the need to copy data to the replica nodes.
- MySQL
- Creating Read Replicas
- When creating a new Read Replica, AWS will take a snapshot of your database.
- If Multi-AZ is not enabled:
- This snapshot will be of your primary database and can cause brief I/O suspension for around 1 minute.
- If Multi-AZ is enabled:
- The snapshot will be of your secondary database and you will not experience any performance hits on your primary database.
- Connecting to Read Replica
- When a new read replica is created you will be able to connect to it using a new end point DNS address.
- Read Replica’s Can Be Promoted
- You can promote a read replica to it’s own standalone database. Doing this will break the replication link between the primary and the secondary.
- Multi-region Read Replicas
- With Amazon Relational Database Service (Amazon RDS), you can create a MySQL, PostgreSQL, or MariaDB Read Replica in a different AWS Region than the source DB instance. You create a Read Replica to do the following:
- Improve your disaster recovery capabilities.
- Scale read operations into a region closer to your users.
- Make it easier to migrate from a data center in one region to a data center in another region.
- You can create an Amazon Aurora DB cluster as a Read Replica in a different AWS Region than the source DB cluster. Taking this approach can improve your disaster recovery capabilities, let you scale read operations into a region that is closer to your users, and make it easier to migrate from one region to another.
- You can create Read Replicas of both encrypted and unencrypted DB clusters. The Read Replica must be encrypted if the source DB cluster is encrypted.
- With Amazon Relational Database Service (Amazon RDS), you can create a MySQL, PostgreSQL, or MariaDB Read Replica in a different AWS Region than the source DB instance. You create a Read Replica to do the following:
- What are Read Replica
- Few More Exam Tips
- You can have up to 5 read replicas.
- You can have read replicas in different REGIONS (with the exception of SQL Server and Oracle).
- For Read Replicas Replication is Asynchronous only, not synchronous.
- Read Replicas can be built off Multi-AZ’s databases.
- BUT Read Replicas themselves cannot be Multi-AZ currently.
- You can have Read Replicas of Read Replicas, however only for MySQL 5.6 and MariaDB and this will further increase latency, PostgreSQL is not currently supported.
- DB Snapshots and Automated backups cannot be taken of read replicas.
- Synchronous replication is used for Multi-AZ
- Asynchronous replication is used for Read Replicas
- If your application does not require transaction support, Atomicity, Consistency, Isolation, Durability (ACID) compliance, joins & SQL, consider using DynamoDB rather than RDS.
- HA for Popular Database
Storage Gateway
How can I backup My Data
- Write backup data to S3 directly, using API calls.
- Write backup data to Storage Gateway, which then securely replicates it to S3.
Three type Storage Gateway Interface
- File Interface
- NFS
- unlimited amount of storage, However maximum file size is 5TB.
- Volume Interface
- Gateway-Cached Volumes
- Gateway-Stored Volumes
- Tape Interface
- Gateway-Virtual Tape Library
- File Interface
Storage Gateway
- File Volumes
- NFS
- Unlimited amount of storage. However maximum file size is 5TB.
- Volume Gateway
- Cached (Gateway-Cached Volumes)
- iSCSI based block storage
- Each Volume can store up to 32TB in Size.
- 32 Volumes supported. 1PB of data can be stored(32*32)
- Stored (Gateway-Stored Volumes)
- iSCSI based block storage
- Each Volume can store up to 16TB in Size.
- 32 Volumes supported. 512TB of data can be stored (32*16)
- Tape Gateway (Gateway-Virtual Tape Library)
- iSCSI based virtual tape solution
- Virtual Tape Library (S3) 1500 virtual tapes (1PB)
- Virtual Tape Shelf (Glacier) unlimited tapes.
- Cached (Gateway-Cached Volumes)
- File Volumes
Storage Gateway Introduction
- File Gateway
File gateway provides a virtual file server, which enables you to store and retrieve Amazon S3 objects through standard file storage protocols. File gateway allows your existing file-based applications or devices to use secure and durable cloud storage without needing to be modified. With file gateway, your configured S3 buckets will be available as Network File System (NFS) mount points. Your applications read and write files and directories over NFS, interfacing to the gateway as a file server.
In turn, the gateway translates these file operations into object requests on your S3 buckets. Your most recently used data is cached on the gateway for low-latency access, and data transfer between your data center and AWS is fully managed and optimized by the gateway. - Gateway-Cached Volumes
You can store your primary data in Amazon S3, and retain your frequently accessed data locally. Gateway-cached volumes provide substantial cost savings on primary storage, minimize the need to scale your storage on-premises, and retain low-latency access to your frequently accessed data. - Gateway-Stored Volumes
In the event you need low-latency access to your entire data set, you can configure your on-premises data gateway to store your primary data locally, and asynchronously back up point-in-time snapshots of this data to Amazon S3. - Gateway-Virtual Tape Library
You can have a limitless collection of virtual tapes. Each virtual tape can be stored in a Virtual Tape Library backed by Amazon S3 or a Virtual Tape Shelf(VTS) backed by Amazon Glacier.
- File Gateway
Storage Gateway - General Facts
- Can be deployed on-premise, or as an EC2 instance.
- Can schedule snapshots.
- You can use Storage Gateway with Direct Connect.
- You can implement bandwidth throttling.
- On-Premise needs with either Vmware’s ESXi or Hyper-V.
- Hardware Requirements:
- 4 or 8vCPUs
- 7.5 GB of RAM
- 75 GB for installation of VM image and system data
Storage Gateway - Storage Requirements
- For gateway-cached volume configuration, you will need storage for the local cache and an upload buffer.
- For gateway-stored volume configuration, you will need storage for your entire dataset and an upload buffer. Gateway-stored volumes can range from 1GiB to 1 TB. Each gateway configured for gateway-stored volumes can support up to 12 volumes and a total volume storage of 16TB.
- For gateway-VTL configuration, you will need storage for the local cache and an upload buffer.
Storage Gateway - Networking Requirements
- Open port 443 on your firewalls.
- Internally, you will need to allow port 80 (activation only), port 3260 (by local systems to connect to iSCSI targets exposed by the gateway) and port UDP 53 (DNS)
Storage Gateway - Encryption
- Data in transit is secured using SSL
- Data at rest can be encrypted using AES-256
Gateway-Cached and Gateway-Stored Volumes
- You can take point-in-time, incremental snapshots of your volume and store them in Amazon S3 in the form of Amazon EBS snapshots.
- Snapshots can be initiated on a scheduled or ad-hoc basis.
- Gateway Stored Snapshots
- If your volume data is stored on-premises, snapshots provide durable, off-site backups in Amazon S3.
- You can create a new Gateway-Stored volume from a snapshot in the event you need to recover a backup.
- You can also use a snapshot of your Gateway-Stored volume as the starting point for a new Amazon EBS volume which you can then attach to an Amazon EC2 instance.
- Gateway Cached Snapshots
- Snapshots can be used to preserve versions of your data, allowing you to revert to a prior version when required or to repurpose a point-in-time version as a new Gateway-Cached volume.
Gateway-Virtual Tape Library Retrieval
The virtual tape containing your data must be stored in a Virtual Tape Library before it can be accessed. Access to virtual tapes in your Virtual Tape Library is instantaneous.If the virtual tape containing your data is in your Virtual Tape Shelf, you must first retrieve the virtual tape from your Virtual Tape Shelf. It takes about 24 Hours for the retrieved virtual tape to be available in the selected Virtual Tape Library.
Gateway-Virtual Tape Library Supports
- Symantec NetBackup version 7.x
- Symantec Backup Exec 2012
- Symantec Backup Exec 2014
- Symantec Backup Exec 15
- Microsoft System Center 2012 R2 Data Protection Manager
- Veeam Backup & Replication V7
- Veeam Backup & Replication V8
- Dell NetVault Backup 10.0
Storage Gateway Exam Tips
- Know the four different Storage Gateway Types:
- File Gateway
- Volume Gateway
- Cached - OLD NAME (Gateway-Cached Volumes)
- Stored - OLD NAME (Gateway-Stored Volumes)
- Tape Gateway - OLD NAME (Gateway-Virtual Tape Library)
- Remember that access to virtual tapes in your virtual tape library are instantaneous. If your tape is in the virtual tape shelf(glacier) it can take 24 hours to get back to your virtual tape library.
- Encrypted using SSL for transit and is encrypted at rest in Amazon S3 using AES-256.
- Gateway-Stored Volumes - stores data as Amazon EBS Snapshots in S3.
- Snapshot can be scheduled.
- Bandwidth can be throttled (good for remote sites)
- You need a storage gateway in each site if using multiple locations.
- Know the four different Storage Gateway Types:
Snowball (Import/Export)
- Snowball
- Types
- Snowball
- Snowball Edge
- Snowmobile
- Understand what Snowball is
- Understand what Import Export is
- Snowball Can
- Import to S3
- Export from S3
- Types
- Import/Export
- Import/Export Disk
- Import to S3, EBS, Glacier
- export from S3
- Import/Export Snowball
- Import to S3
- Export to S3
- Import/Export Disk
- Snowball
Automated Backups
- AWS Services and Automated Backups
- Services that have Automated Backup
- RDS
- Elasticache (Redis only)
- Redshift
- Services that do not have Automated Backup
- EC2
- RDS Automated Backups
- For MySQL you need innoDB (transactional engine)
- There is a performance hit if Multi-AZ is not enabled
- If you delete an instance, then ALL automated backups are deleted
- However, manual DB snapshots will NOT be deleted
- All stored on S3
- When you do a restore, you can change the engine type (SQL Standard to SQL Enterprise for example). Provided you have enough storage space
- Elasticache Backups
- Available for Redis Cache Cluster only
- The entire cluster is snapshotted
- Snapshot will degrade performance
- Therefore only set your snapshot window during the least busy part of the day
- Stored on S3
- Redshift Backups
- Stored on S3
- By default, Amazon Redshift enables automated backups of your data warehouse cluster with a 1-day retention period
- Amazon Redshift only backs up data that has changed so most snapshots only use up a small amount of your free backup storage
- EC2
- No automated backups
- Backups degrade you performance, schedule these times wisely
- Snapshots are stored in S3
- Can create automated backups using either the command line interface or Python
- They are incremental:
- Snapshots only store incremental changes since last snapshot
- Only charged for incremental storage
- Each snapshot still contains the base snapshot data
- Services that have Automated Backup
- AWS Services and Automated Backups
Domain 1 - Summary
- Domain 1
- Domain 1.0: High Availability and Business Continuity
- Demonstrate ability to architect the appropriate level of availability based on stakeholder requirements
- 1.2 Demonstrate ability to implement DR for systems based on RPO and RTO
- 1.3 Determine appropriate use of multi-Availability Zones vs. multi-Region architectures
- 1.4 Demonstrate ability to implement self-healing capabilities
- 15% of the exam
Domain 2 -Costing - 5%
Cross Account Access Role & Permissions
- Steps
- Identify our account numbers
- Create a group in IAM - Dev
- Create a user in IAM - Dev
- Log in to Production
- Create the “read-write-app-bucket” policy
- Create the “UpdateApp” Cross Account Role
- Apply the newly created policy to the role
- Log in to the Developer Account
- Create a new inline policy
- Apply it to the Developer group
- Login as John
- Switch Accounts
- Steps
AWS Organizations & Consolidated Billing
- AWS Organizations
AWS Organizations is an account management service that enables you to consolidate multiple AWS accounts into an organization that you create and centrally manage.- Available in two feature sets:
- Consolidated Billing
- ALL Features
- consist of
- Root
- Organization Unit (OU)
- AWS Account
- Available in two feature sets:
- Consolidated Billing
- Accounts
- Paying Account (Paying account is independent. Cannot access resources of the other accounts)
- Linked Accounts (All linked accounts are independent)
- Advantages
- One bill per AWS account
- Very easy to track charges and allocate costs
- Volume pricing discount
- S3 pricing
- Reserved EC2 Instances
- Best Practices
- Always enable multi-factor authentication on root account.
- Always use a strong and complex password on root account.
- Paying account should be used for billing purposes only. Do not deploy resources in to paying account.
- Notes
- Linked Accounts
- 20 linked accounts only
- To add more visit https://aws-portal.amazon.com/gp/aws/html-forms-controller/contactus/aws-account-and-billing
- Billing Alerts
- When monitoring is enabled on the paying account the billing data for all linked accounts is included
- You can still create billing alerts per individual account
- CloudTrail
- Per AWS Account and is enabled per region.
- Can consolidate logs using an S3 bucket.
- Turn on CloudTrail in the paying account
- Create a bucket policy that allows cross account access
- Turn on CloudTrail in the other accounts and use the bucket in the paying account
- Linked Accounts
- Exam Tips:
- Consolidated billing allows you to get volume discounts on all your accounts.
- Unused reserved instances for EC2 are applied across the group.
- CloudTrail is on a per account and per region basis but can be aggregate in to a single bucket in the paying account.
- Accounts
- AWS Organizations
Tagging & Resource Groups
- What Are Tags
- Key Value Pairs attached to AWS resources
- Metadata (data about data)
- Tags can sometimes be inherited
- Autoscaling, CloudFormation and Elastic Beanstalk can create other resources
- What Are Resource Groups
- Resource groups make it easy to group your resources using the tags that are assigned to them. You can group resources that share one or more tags.
- Resource groups contain information such as:
- Region
- Name
- Health Checks
- Specific information
- For EC2 - Public & Private IP Addresses
- For ELB - Port Configurations
- For RDS - Database Engine etc.
- What Are Tags
Reserved Instance for EC2 & RDS
- EC2
- EC2 - Pricing Models
- On Demand - allow you to pay a fixed rate by the hour with no commitment.
- Reserved - provide you with a capacity reservation, and offer a significant discount on the hourly charge for an instance 1 year or 3 year terms.
- Spot - enable you to bid whatever price you want for instance capacity, providing for even greater savings if your applications have flexible start and end times.
- Dedicated - Dedicated Instances are Amazon EC2 instances that run in a virtual private cloud (VPC) on hardware that’s dedicated to a single customer. Your Dedicated Instances are physically isolated at the host hardware level from your instances that aren’t Dedicated Instances and from instances that belong to other AWS accounts.
- EC2 - Pricing Models detail
- On Demand
- Users that want the low cost and flexibility of Amazon EC2 without any up-front payment or long-term commitment
- Applications with short term, spiky, or unpredictable workloads that cannot be interrupted.
- Applications being developed or tested on Amazon EC2 for the first time
- Reserved
- Applications with steady state or predictable usage
- Applications that require reserved capacity
- Users able to make upfront payments to reduce their total computing costs even further.
- Spot
- Applications that have flexible start and end times
- Applications that are only feasible at very low compute prices
- Users with urgent computing needs for large amounts of additional capacity
- On Demand
- Understanding Reserved Instances
- All Up Front = Largest Discount (Up to 75%)
- Partial Up Front = Middle Discount
- No Upfront = Least Discount (Still cheaper than on demand)
- Different Types of RIs
- Standard RIs
- These provide the most significant discount (up to 75% off On-Demand) and are best suited for steady-state usage.
- Convertible RIs
- These provide a discount (up to 45% off On-Demand) and the capability to change the attributes of the RI as long as the exchange results in the creation of Reserved Instances of equal or greater value. Like Standard RIs, Convertible RIs are best suited for steady-state usage.
- Scheduled RIs
- These are available to launch within the time windows you reserve. This option allows you to match your capacity reservation to a predictable recurring schedule that only requires a fraction of a day, a week, or a month.
- Convertible RIs
- Change instance families, operating system, tenancy and payment option
- Standard RIs
- Understanding Reserved Instances
- You can modify reserved instances
- Switching Availability Zones
- Change the instance type within the same instance family
- You can modify reserved instances
- Change Your Reserved Instances
- You can change your standard reserved instances by submitting a modification request. This request will be processed providing the footprint remains the same. This is calculated by using normalization factors.
- Normalization Factors
- Each Reserved Instance has an instance size footprint, which is determined by the normalization factor of the instance type and the number of instances in the reservation.
- A modification request is not processed if the footprint of the target configuration does not match the size of the original configuration. In the Amazon EC2 console, the footprint is measured in units.
- Example:
- Take the quantity of reserved instances and multiply it by the normalization factor.
- So a quantity of 2 large instances = (2*4) = 8
- This can be changed to 8 small instances (8*1) or 4 medium instances (2*4)
- Reserved Instances can only be modified if they are within the SAME family
- EC2 - Pricing Models
- RDS
RDS - Reserved Instances
- Each reservation is associated with the following set of attributes:
- DB Engine
- DB Instance class
- Deployment type
- License Model
- Region
- Each reservation can only be applied to a DB Instance with the same attributes for the duration of the term. If you decide to modify any of these attributes of your running DB Instance class before the end of the reservation term, your hourly usage rates for that DB Instance will revert to on demand hourly rates.
- If you later modify the running DB Instance’s attributes to match those of the original reservation, or create a new DB Instance with the same attributes as your original reservation, your reserved pricing will be applied to it until the end of your reservation term.
- You can have reserved instances for RDS Multi-AZ’s as well as Read Replicas.
- For Read Replica’s the DB instance class and region must be the same.
- Each reservation is associated with the following set of attributes:
RDS - Move AZs
- Each Reserved Instance is associated with a specific Region, which is fixed for the lifetime of the reservation and cannot be changed. Each reservation can, however, be used in any of the available AZs within the associated Region.
- Exam Tips
- Largest discount is applied for all Upfront (up to 75%)
- Contract length is 1 or 3 years. The longer the contract, the more you save.
- Three types of RIs
- Standard, Convertible & Scheduled
- Standard RIs for EC2 can be modified, but only if they are in the same family and only if the normalization factors are equal and only for linux (excluding RedHat or SUSE Linux)
- Therefore it is better to purchase an RI with more capacity than you actually need, so as to allow for growth.
- You can switch EC2 RIs between AZs, but not between regions.
- You can sell EC2 RIs on https://aws.amazon.com/ec2/purchasing-options/reserved-instances/marketplace/
- You can have reserved RDS instances
- You can move AZ’s but not regions
- Understand the different use cases of reserved, on demand & spot instances.
- Typically you only want to use on demand instances for things like autoscaling. Spot is going to be the cheapest way of doing something, but is might not be the best answer technically.
- Read the question carefully. Is it asking you what is the most commercially feasible way of designing a solution, or is it asking for high availability with low RTO/RPOs.
- Knowing the different instance type by name REALLY helps.
- EC2
Knowing your EC2 Instance Type
- EC2 Instance Types
Family Speciality Use case D2 Dense Storage Fileservers/Data Wareshousing/Hadoop R4 Memory Optimized Memory Intensive Apps/DBs M4 General Purpose Application Servers C4 Compute Optimized CPU Intensive Apps/DBs G2 Graphics Intensive Video Encoding/3D Application Streaming I2 High Speed Storage NoSQL DBs, Data Warehousing etc F1 Field Programmable Gate Array Hardware acceleration for your code T2 Lowest Cost, General Purpose Web Servers/Small DBs P2 Graphics/General Purpose GPU Machine Learning, Bit Coin Mining etc X1 Memory Optimize SAP HANA/Apache Spark etc - How to remember Instance type
- D for Density
- R for RAM
- M - main choice for general purpose apps
- C for Compute
- G - Graphics
- I for IOPS
- F for FPGA
- T cheap general purpose (think T2 micro)
- P - Graphics (think Pics)
- X - Extreme Memory
- DR Mc GIFT PX
Domain 2 Summary
- Domain 2.0: Costing
- 2.1 Demonstrate ability to make architectural decisions that minimize and optimize infrastructure cost
- 2.2 Apply the appropriate AWS account and billing set-up options based on scenario
- 2.3 Ability to compare and contrast the cost implications of different architectures
- 5% of the exam
- Steps To Enable Cross Account Access
- If you need a custom policy (such as read and write access to a custom S3 bucket) create this policy first.
- Create role with cross account access
- Apply the policy to that role and note down the ARN.
- Grant access to the Role
- Switch to the Role
- https://docs.aws.amazon.com/IAM/latest/UserGuide/tutorial_cross-account-with-roles.html
- https://aws.amazon.com/blogs/security/how-to-enable-cross-account-access-to-the-aws-management-console/
- Domain 2.0: Costing
Domain 3 - Deployment Management - 10%
CloudFormation
- READ the CloudFormation FAQs: https://aws.amazon.com/cloudformation/faqs/ and do the deep dive lab
- What is CloudFormation?
- One of the most powerful parts of AWS, CloudFormation allows you to take what was once traditional hardware infrastructure and convert it into code.
- CloudFormation gives developers an systems administrators an easy way to create and manage a collection of related AWS resources, provisioning and updating them in an orderly and predictable fashion.
- You don’t need to figure out the order for provisioning AWS services or the subtleties of making those dependencies work. CloudFormation takes care of this for you.
- After the AWS resources are deployed, you can modify and update them in a controlled and predictable way, in effect applying version control to your AWS infrastructure the same way you do with your software.
- CloudFormation Stack vs. Template
- A CloudFormation Template is essentially an architectural diagram an a CloudFormation Stack is the end result of that diagram (i.e. what is actually provisioned).
- You create, update and delete a collection of resources by creating, updating an deleting stacks using CloudFormation templates.
- CloudFormation templates are in the JSON format or YAML.
- Elements Of A Template
- Mandatory Elements
- List of AWS Resources and their associated configuration values
- Optional Elements
- The template’s file format & version number
- Template Parameters
- The input values that are supplied at stack creation time. Limit of 60.
- Output Values
- The output values required once a stack has finished building (such as the public IP address, ELB address, etc.) Limit of 60.
- List of data tables
- Used to look up static configuration values such as AMI’s etc.
- Mandatory Elements
- Outputting Data
- You can use Fn:GetAtt to output data.
1
2
3
4
5
6
7
8
9"Public": {
"Description": "Public IP address of the web server",
"Value": {
"Fn::GetAtt":[
"WebServerHost",
"PublicIp"
]
}
}
- You can use Fn:GetAtt to output data.
- Chef & Puppet Integration
- Cloud Formation supports Chef & Puppet Integration, meaning that you can deploy and configure right down to the application layer.
- Bootstrap scripts are also supported enabling you to install packages, files, an services on your EC2 instances by simply describing them in your CloudFormation template.
- Stack Creation Errors
- By Default, the **”automatic rollback on error” feature is enabled. This will cause all AWS resources that AWS CloudFormation created successfully for a stack up to the point where an error occurred to be deleted.
- You will be charged for resources that are provisioned, even if there is an error.
- CloudFormation, itself, is free.
- Stacks Can Wait For Applications
- AWS CloudFormation provides a WaitCondition resources that acts as a barrier, blocking the creation of other resources until a completion signal is received from an external source, such as your application or management system.
- You can Specify Deletion Policies
- AWS CloudFormation allows you to define deletion policies for resources in the template. You can specify that snapshots be created for Amazon EBS volumes or Amazon RDS database instances before they are deleted.
- You can also specify that a resource should be preserved and not deleted when the stack is deleted. This is useful for preserving Amazon S3 buckets when the stack is deleted.
- You Can Update Your Stack After It Is Created
- You can use AWS CloudFormation to modify and update the resources in your existing stacks in a controlled and predictable way. By using templates to manage your stack changes, you have the ability to apply version control to your AWS infrastructure, just as you do with the software running on it.
- CloudFormation & Roles
- CloudFormation can be used to create roles in IAM.
1
2
3
4
5
6
7
8
9{
"Type": "AWS::IAM::Role",
"Properties":{
"AssumeRolePolicyDocument": { JSON },
"ManagedPolicyArns": [String,...],
"Path": String,
"Policies": [Policies,...]
}
} - CloudFormation can be used to grant EC2 instances access to roles.
- CloudFormation can be used to create roles in IAM.
- VPCs Can Be Created And Customized
- CloudFormation supports creating VPCs, Subnets, Gateways, Route Tables and Network ACLs, as well as creating resources such as Elastic IPs, Amazon EC2 Instances, EC2 Security Groups, Auto Scaling Groups, Elastic Load Balancers, Amazon RDS Database Instances, and Amazon RDS Security Groups in a VPC.
- You can specify IP address ranges both in terms of CIDR ranges as well as individual IP addresses for specific instances. You can specify pre-existing EIPs.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"AWSTemplateFormatVersion" : "2010-09-09",
"Description" : "Simple Standalone ENI",
"Resources" : {
"myENI" : {
"Type" : "AWS::EC2::NetworkInterface",
"Properties" : {
"Tags": [{"Key":"foo","Value":"bar"}],
"Description": "A nice description.",
"SourceDestCheck": "false",
"GroupSet": ["sg-75zzz219"],
"SubnetId": "subnet-3z648z53",
"PrivateIpAddress": "10.0.0.16"
}
}
}
}
- VPC Peering
- You can create multiple VPCs inside one template.
- You can enable VPC Peering using CloudFormation, but only within the same AWS Account.
- Route53 Supported
- You can create new hosted zones or update existing hosted zones using CloudFormation Templates.
- This includes adding or changing items such as A records, Aliases, CNAMEs, etc.
- Exam Tips
- CloudFormation - a big topic in the exam.
- Know all the services that are supported.
- Remember what is mandatory for a template - “Resources”
- You can create multiple VPCs inside one template.
- You can enable VPC Peering using CloudFormation, but only within the same AWS Account.
- Chef, Puppet & Bootstrap Scripts are supported.
- You can use Fn::GetAtt to output data.
- By default, the “automatic rollback on error” feature is enabled.
- You are charged for errors.
- CloudFormation is free.
- Stacks can wait for applications to be provisioned using the “WaitCondition”.
- Route53 is completely supported. This includes creating new hosted zones or updating existing ones.
- You can create A Records, Aliases etc.
- IAM Role Creation and Assignment is also supported.
- CloudFormation material
- CloudFormation Basic
- http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/gettingstarted.templatebasics.html
- Learn about the following about templates:
- Declaring resources and their properties
- Referencing(提取) other resources with the Ref function and resource attributes using the Fn::GetAtt function
- Using parameters to enable users to specify values at stack creation time and using constraints to validate parameter input
- Using mappings to determine conditional values
- Using the Fn::Join function to construct values based on parameters, resource attributes, and other things
- Using output values based to capture information about the stack’s resources.
- CloudFormation intrinsic Function
- Fn::Base64
- returns the Base64 representation of the input string. this function is typically used to pass encoded data to Amazon EC2 instances by way of the UserData property.
- JSON Format { “Fn::Base64” : valueToEncode }
- Fn::FindInMap
- returns the value corresponding to keys in a two-level map that is declared in the Mapping section.
- JSON Format { “Fn::FindInMap” : [ “MapName”, “TopLevelKey”, “SecondLevelKey”] }
- Fn::GetAtt
- returns the value of an attribute from a resource in the template
- JSON Format { “Fn::GetAtt” : [ “logicalNameOfResource”, “attributeName” ] }
- Fn::Join
- Fn::Join appends a set of values into a single value, separated by the specified delimiter. If a delimiter is the empty string, the set of values are concatenated with no delimiter.
- JSON Format { “Fn::Join” : [ “delimiter”, [ comma-delimited list of values ] ] }
- JSON example {“Fn::Join” : [ “:”, [ “a”, “b”, “c” ] ]} will returns “a:b:c”
- Fn::Select
- returns a single object from a list of objects by index
- JSON Format { “Fn::Select” : [ index, listOfObjects ] }
- JSON example { “Fn::Select” : [ “1”, [ “apples”, “grapes”, “oranges”, “mangoes” ] ] } will returns “grapes”
- Fn::Split
- To split a string into a list of string values so that you can select an element from the resulting string list.
- JSON Format { “Fn::Split” : [ “delimiter”, “source string” ] }
- JSON example { “Fn::Split” : [ “|” , “a|b|c” ] } will return [“a”, “b”, “c”]
- Fn::Sub
- 将输入字符串中的变量替换为您指定的值
- JSON Format { “Fn::Sub” : [ String, { Var1Name: Var1Value, Var2Name: Var2Value } ] }
- JSON example - 将AWS::Region和AWS::StackName替换为实际的值
- Fn::Base64
1
2
3
4
5
6"UserData": { "Fn::Base64": { "Fn::Join": ["\n", [
"#!/bin/bash -xe",
"yum update -y aws-cfn-bootstrap",
{ "Fn::Sub": "/opt/aws/bin/cfn-init -v --stack ${AWS::StackName} --resource LaunchConfig --configsets wordpress_install --region ${AWS::Region}" },
{ "Fn::Sub": "/opt/aws/bin/cfn-signal -e $? --stack ${AWS::StackName} --stack ${AWS::StackName} --resource WebServer --region ${AWS::Region}" }]]
}}- Ref - returns the value of the specified parameter or resource. - When you specify a parameter's logical name, it returns the value of the parameter. - When you specify a resource's logical name, it returns a value that you can typically use to refer to that resource, such as a physical ID. - JSON Format { "Ref" : "logicalName" }- CloudFormation limit
- You can include up to 60 parameters and 60 outputs in a template.
- There are no limit to the number of templates.
- Each AWS CloudFormation account is limited to a maximum of 200 stacks.
- CloudFormation – Ref, Fn::Join, GetAtt, Fn::split, Fn::select and etc function
- CloudFormation Basic
Elastic Beanstalk
- Elastic Beanstalk
- AWS Elastic Beanstalk makes it even easier for developers to quickly deploy and manage applications in the AWS cloud. Developers simply upload their application, and Elastic Beanstalk automatically handles the deployment details of capacity provisioning, load balancing, auto-scaling, and application health monitoring.
- Difference Between CloudFormation & Elastic Beanstalk?
- CloudFormation supports Elastic Beanstalk, but Elastic Beanstalk will not provision CloudFormation Templates.
- Supported Languages * Stacks
- Packer Builder
- Apache
- Apache Tomcat for Java applications (Java 6,7 & 8)
- Apache HTTP Server for PHP applications (PHP 5.4 - 7.0)
- Apache HTTP Server for Python applications
- Nginx or Apache HTTP Server for Node.js applications
- Docker
- Single Container Docker
- Multicontainer Docker
- Preconfigured Docker
- Ruby (Passenger or Puma) (Ruby 1.9 - 2.3)
- Go 1.6
- Java with Tomcat
- Java SE (Java 7 & 8)
- .NET on Windows Server with IIS 7.5, 8.0 and 8.5
- Node.js (nginx & Apache)
- Python (2.6 - 3.4)
- PHP
- What Can Be Controlled With Elastic Beanstalk
- Access built-in Amazon CloudWatch monitoring and get notifications on application health and other important events
- Adjust application server settings (e.g. JVM settings) and pass environment variables
- Run other application components, such as a memory caching service, side-by-side in Amazon EC2
- Access log files without logging in to the application servers
- Provisioning With Elastic Beanstalk
- You can simply upload your deployable code (e.g. WAR file) or push your Git repository, and AWS Elastic Beanstalk does the rest. The AWS Toolkit for Visual Studio and the AWS Toolkit for Eclipse allow you to deploy your application to AWS Elastic Beanstalk and manage it, without leaving your IDE.
- Updating Elastic Beanstalk
- You can push out updates from GIT: only the modified files are transmitted to AWS Elastic Beanstalk.
- Elastic Beanstalk is designed to support multiple running environments such as one for integration testing, one for pre-production, and one for production. Each environment is independently configured and runs on its own separate AWS resources. Elastic Beanstalk also stores and tracks application versions over time, so an existing environment can be easily rolled back to a prior version or a new environment can be launched using an older version to try and reproduce a customer problem.
- How Does It Work?
- Elastic Beanstalk stores your application files and, optionally, your server log files in Amazon S3. If you are using the AWS Management Console, Git, the AWS Toolkit for Visual Studio, or AWS Toolkit for Eclipse, an Amazon S3 bucket will be created in your account, and the files you upload will be automatically copied from your local client to Amazon S3.
- Optionally, you may configure Elastic Beanstalk to copy your server log files every hour to Amazon S3. You do this by editing the environment configuration settings.
- Can It Store Application Data Like Images?
- You can use Amazon S3 for application storage. The easiest way to do this is by including the AWS SDK as part of your application’s deployable file. For example, you can include the AWS SDK for Java as port of your application’s WAR file.
- Can Elastic Beanstalk Provision RDS Instances?
- Yes: Elastic Beanstalk can automatically provision an Amazon RDS DB Instance. The connectivity information to the DB Instance is exposed to your application by environment variables.
- Elastic Beanstalk Fault Tolerance
- Elastic Beanstalk can be configured to be fault tolerant within a single region using multiple availability zones.
- Elastic Beanstalk Security
- By default, your application is available publicly at myapp.elasticbeanstalk.com
- Integrates with AWS VPC. You can then restrict who can access the app via white-listed IP addresses (either at the security group level or NACL level.)
- Exam Tips
- Elastic Beanstalk can provision RDS instances
- Elastic Beanstalk supports IAM
- Elastic Beanstalk supports VPC
- You have full access to the resources under Elastic Beanstalk
- Code is stored in S3
- Multiple environments are allowed to support version control. You can roll back changes.
- Only the changes from Git repositories are replicated.
- Amazon Linux AMI & Windows 2012 R2 supported.\
- Elastic Beanstalk
OpsWorks
What is OpsWorks
- Cloud-based applications usually require a group of related resources—application servers, database servers, and so on—that must be created and managed collectively. This collection of instances is called a stack. A simple application stack might look something like the following.
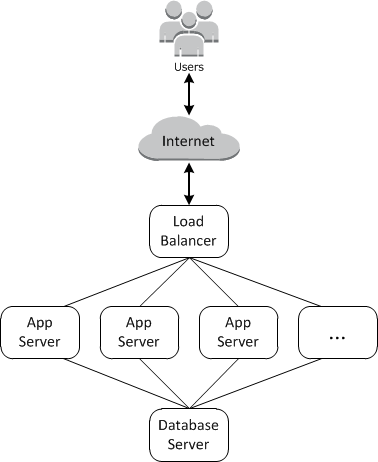
- AWS OpsWorks Stacks provides a simple and straightforward way to create and manage stacks and their associated applications and resources
- Amazon Definition:
- AWS OpsWorks is an application management service that helps you automate operational tasks like code deployment, software configurations, package installations, database setups, and server scaling using Chef. OpsWorks gives you the flexibility to define your application architecture and resource configuration and handles the provisioning and management of your AWS resources for you. OpsWorks includes automation to scale your application based on time or load, monitoring to help you troubleshoot and take automated action based on the state of your resources, and permissions and policy management to make management of multi-user environments easier.
- Cloud-based applications usually require a group of related resources—application servers, database servers, and so on—that must be created and managed collectively. This collection of instances is called a stack. A simple application stack might look something like the following.
What is Chef
- Chef turns infrastructure into code. With Chef, you can automate how you build, deploy, and manage your infrastructure. Your infrastructure becomes as versionable, testable, and repeatable as application code.
- Chef server stores your recipes as well as other configuration data. The Chef client is installed on each server, virtual machine, container, or networking device you manage - we’ll call these nodes. The client periodically polls Chef server latest policy and state of your network. If anything on the node is out of date, the client brings it up to date.
What is OpsWorks
- A GUI to deploy and configure your infrastructure quickly. OpsWorks consists of two elements, Stacks and Layers.
- A stack is a container (or group) of resources such as ELBs, EC2 instances, RDS instances etc.
- A layer exists within a stack and consists of things like a web application layer. An application processing layer or a Database layer.
- When you create a layer, rather than going and configuring everything manually (like installing Apache, PHP etc) OpsWorks takes care of this for you.
Layers
- 1 or more layers in the stack
- An instance must be assigned to at least 1 layer
- Which chef layers run, are determined by the layer the instance belongs to
- Preconfigured Layers include:
- Applications
- Databases
- Load Balancers
- Caching
Domain 3
- Domain 3.0: Deployment Management
- 3.1 Ability to manage the lifecycle of an application on AWS
- 3.2 Demonstrate ability to implement the right architecture for development, testing, and staging environments
- 3.3 Position and select most appropriate AWS deployment mechanism based on scenario
- OpsWorks Exam Tips:
- Do the OpsWorks Lab
- You need to know the difference between:
- A Stack
- A Layer
- A Recipe
- Domain 3.0: Deployment Management
Domain 4 - Network Design - 10%
VPC
What You Should Know Already
- What a VPC is
- How to build your own VPC
- How to make a subnet public
- How to make a subnet private
- What a NAT is
- Disable Source/Destination Checks
- What a route table is
- Subnets can communicate with each other by default
Basic Info
- Think of a VPC as a logical datacenter in AWS
- Consists of IGW’s (Or Virtual Private Gateways), Route Tables, Network Access Control Lists, Subnets, Security Groups
- 1 Subnet = 1 Availability Zone
- Security Groups are Stateful, Network Access Control Lists are Stateless.
- Can Peer VPCs both in the same account and with other AWS accounts.
- No Transitive Peering
- Custom VPC network block size has to be between a /16 netmask and /28 netmask.
What can you do with a VPC
- Launch instances into a subnet of your choosing
- Assign custom IP address ranges in each subnet
- Configure route tables between subnets
- Create internet gateway and attach it to our VPC
- Much better security control over your AWS resources
- Instance security groups
- Subnet network access control lists (ACLS)
Default VPC vs Custom VPC
- Default VPC is user friendly, allowing you to immediately deploy instances
- All Subnets in default VPC have a route out to the internet.
- Each EC2 instance has both a public and private IP address
- If you delete the default VPC the only way to get it back is to contact AWS.
VPC peering
- Allows you to connect one VPC with another via a direct network route using private IP addresses.
- Instances behave as if they were on the same private network
- You can peer VPC’s with other AWS accounts as well as with other VPCs in the same account.
- Peering is in a star configuration, ie 1 central VPC peers with 4 others, NO TRANSITIVE PEERING!!!
Create VPC
- things automatically created
- Route tables
- Network ACLs
- Security Groups
- DHCP options set
- things are not automatically created
- Internet Gateways
- Subnets
- things automatically created
VPC Subnet
- There are 5 IP address reserved in each subnet by AWS, take CIDR block 10.0.0.0/24 as example
- 10.0.0.0 Network address
- 10.0.0.1 Reserved by AWS for the VPC router
- 10.0.0.2 Reserved by AWS for DNS
- 10.0.0.3 Reserved by AWS for future use.
- 10.0.0.255 Network broadcast address, we do not support broadcast in a VPC, therefore we reserve this address.
- There are 5 IP address reserved in each subnet by AWS, take CIDR block 10.0.0.0/24 as example
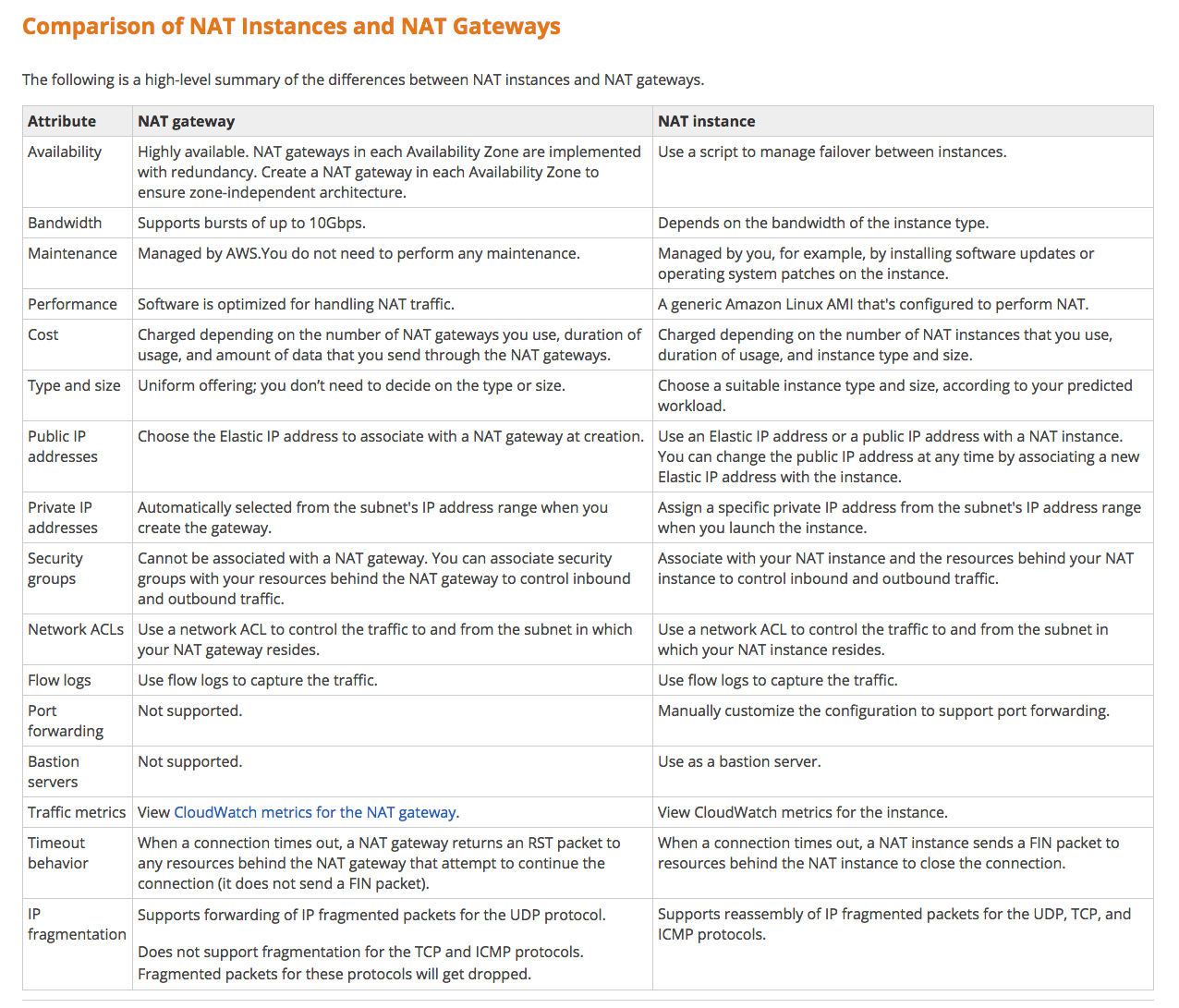
NAT instances
- When creating a NAT instance, Disable Source/Destination Check on the Instance
- NAT instance must be in a public subnet
- Must have an elastic IP address to work
- There must be a route out of the private subnet to the NAT instance, in order for this to work
- The amount of traffic that NAT instances supports, depends on the instance size. If you are bottlenecking, increase the instance size
- You can create high availability using Autoscaling Groups, multiple subnets in different AZ’s and a script to automate failover
- Behind a Security Group.
NAT Gateways
- Very new
- Preferred by the enterprise
- Scale automatically up to 10Gbps
- No need to patch
- Not associated with security groups
- Automatically assigned a public ip address
- Remember to update your route tables.
- No need to disable Source/Destination Checks.
NAT instances vs NAT Gateways
Network ACL’s
- Your VPC automatically comes a default network ACL and by default it allows all outbound and inbound traffic.
- You can create a custom network ACL. By default, each custom network ACL denies all inbound and outbound traffic until you add rules.
- Each subnet in your VPC must be associated with a network ACL. If you don’t explicitly associate a subnet with a network ACL, the subnet is automatically associated with the default network ACL.
- You can associate a network ACL with multiple subnets; however, a subnet can be associated with only one network ACL at a time. When you associate a network ACL with a subnet, the previous association is removed.
- A network ACL contains a numbered list of rules that is evaluated in order, starting with the lowest numbered rule.
- A network ACL has separate inbound and outbound rules, and each rule can either allow or deny traffic.
- Network ACLs are stateless responses to allowed inbound traffic are subject to the rules for outbound traffic (and vice versa)
- Block IP Addresses using network ACL’s not Security Groups
Security Group vs Network ACL

NAT vs Bastions
- A NAT is used to provide internet traffic to EC2 instances in private subnets
- A Bastion is used to securely administer EC2 instance (using SSH or RDP) in private subnets. In Australia we call them jump boxes.
Resilient Architecture
- If you want resiliency, always have 2 public subnets and 2 private subnets. Make sure each subnet is in different availability zones.
- With ELB’s make sure they are in 2 public subnets in 2 different availability zones.
- With Bastion hosts, put them behind an autoscaling group with a minimum size of 2. Use Route53 (either round robin or using a health check) to automatically fail over.
- NAT instances are tricky to make resilient. You need 1 in each public subnet, each with their own public IP address, and you need to write a script to fail between the two. Instead where possible, use NAT gateways.
VPC Flow Logs
- You can monitor network traffic within your custom VPC’s using VPC Flow Logs.
VPC limit
- Currently you can create 200 subnets per VPC by default
VPC Peering
- What is VPC Peering
- VPC Peering is simply a connection between two VPCs that enables you to route traffic between them using private IP addresses. Instances in either VPC can communicate with each other as if they are within the same network. You can create a VPC peering connection between your own VPCs, or with a VPC in another AWS account within a single region.
- AWS uses the existing infrastructure of a VPC to create a VPC peering connection; it is neither a gateway nor a VPN connection, and does not rely on a separate pieces of physical hardware. There is no single point of failure for communication or a bandwidth bottleneck.
- Transitive Peering NOT Supported
- VPC Peering Limitations
- Soft limit of 50 VPC peers per VPC, can be increased to 125 by request.
- You cannot create a VPC peering connection between VPCs that have matching or overlapping CIDR blocks.
- You cannot create a VPC peering connection between VPCs in different regions.
- VPC peering does not support transitive peering relationships.
- A placement group can span peered VPCs; however, you will not get full bandwidth between instances in peered VPCs.
- Private DNS values cannot be resolved between instances in peered VPCs.
- Steps To Setup VPC Peering
- Owner of the local VPC sends a request to the owner of the second VPC to peer.
- Owner of the second VPC has to accept.
- Owner of the local VPC adds a route to their route table allowing their subnets to route out to the peer VPC
- Owner of the peer VPC adds a route to their route table allowing their subnets to route back to the other VPC.
- Security Groups in both VPCs have to both allow traffic.
- Troubleshooting
- Setting up the peer:
- Are the VPCs in the same region?
- If you can’t create a VPC peer, check to see if the CIDR blocks are overlapping.
- After the peer is setup:
- Check that the relevant security groups and NACLs are allowing traffic through.
- Check that a route has been created in BOTH VPCs routing tables.
- Setting up the peer:
- Exam Tips
- Remember the steps to setting up a VPC peer.
- Remember how to troubleshoot issues with VPC peering.
- What is VPC Peering
Direct Connect
What is Direct Connect https://aws.amazon.com/directconnect/?nc1=h_ls
- AWS Direct Connect makes it easy to establish a dedicated network connection from your premises to AWS. Using AWS Direct Connect, you can establish private connectivity between AWS and your datacenter, office, or colocation environment, which in many cases can reduce your network costs, increase bandwidth throughput, and provide a more consistent network experience than Internet-based connections.
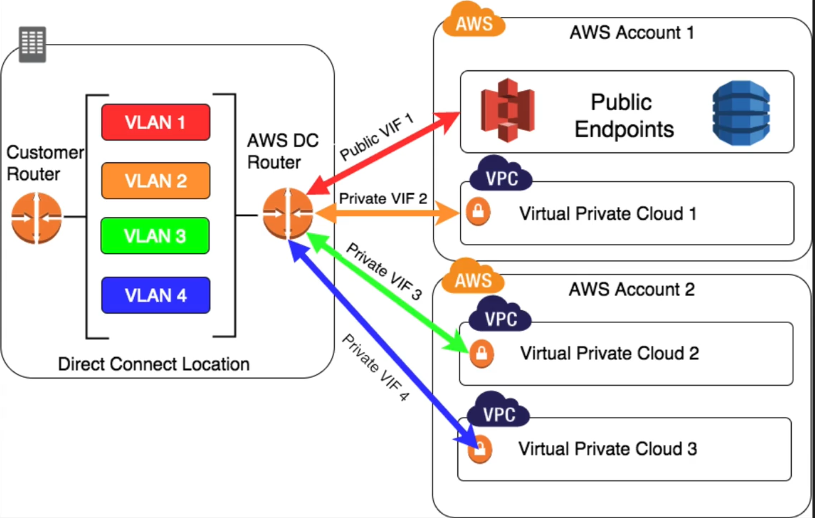
- AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces.
- This allows you to use the same connection to access public resources such as objects stored in Amazon S3 using public IP address space, and private resources such as Amazon EC2 instances running within an Amazon Virtual Private Cloud (VPC) using private IP space, while maintaining network separation between the public and private environments. Virtual interfaces can be reconfigured at any time to meet your changing needs.
Direct Connect Benefits
- Reduce costs when using large volumes of traffic
- Increase reliability
- Increase bandwidth
How Is Direct Connect Different From A VPN?
- VPN Connections can be configured in minutes and are a good solution if you have an immediate need, have low to modest bandwidth requirements, and can tolerate the inherent variability in Internet-based connectivity.
- AWS Direct Connect does not involve the Internet. Instead, it uses dedicated, private network connections between your intranet and Amazon VPC.
Direct Connect Connections
- Available In:
- 10 Gbps
- 1 Gbps
- Sub 1Gbps can be purchased through AWS Direct Connect Partners
- Uses Ethernet VLAN trunking (802.1Q)
- This dedicated connection can be partitioned in to multiple virtual interfaces (VIFs)
- Allows public connections to EC2 or S3 using public IP addresses
- Allows private connections to VPC using internal IP addresses
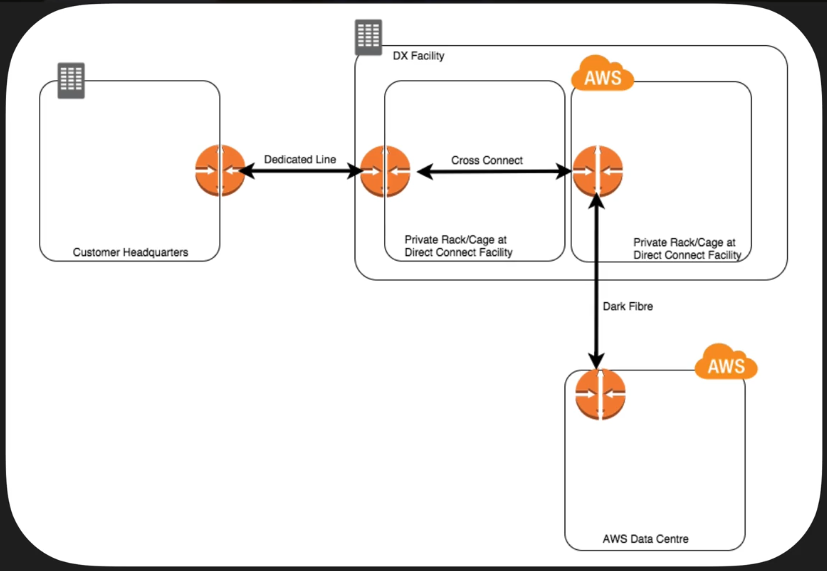
- Use BGP to Fail Over Automatically from Direct Connect to Site to Site VPN
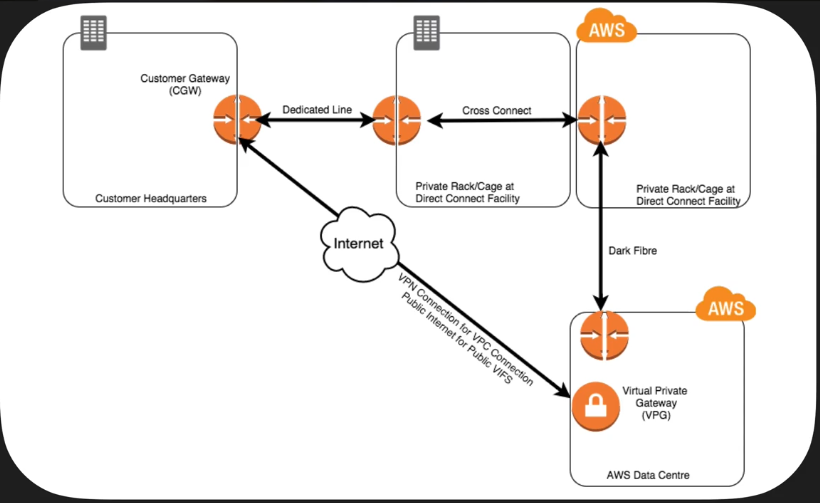
- Available In:
CGW vs. VPG
- When using a VPN to connect to a VPC, you need an anchor on each side of that connection. A Customer Gateway is the anchor on your side of that connection. It can be a physical or software appliance.
- The anchor on the AWS side of the VPN connection is called a Virtual Private Gateway.
Key Points To Remember
- If you are accessing public services using HTTPS endpoints (think DynamoDB, S3) then use public VIFs.
- If you are accessing VPCs using private IP address ranges, then use private VIFs.
- In the US, you only need 1 direct connect connection to connect in to all 4 US regions. Data transferred between regions goes over AWS’s internal lines, not the public internet.
- Direct connect itself is not redundant. You can add redundancy by having 2 connections(2 routes, 2 direct connects), or by having a site-to-site VPN in place.
- Layer 2 connections are not supported.
- Know the difference between a Customer Gateway CGW (Customer side) and Virtual Private Gateway (AWS side.)
HPC & Enhanced Networking
- HPC - Guide Lines
High performance compute is used by many different industries, such as the pharmaceutical or automotive industries. HPC typically involves:- Batch processing with large and compute intensive workloads
- Demands High Performance CPU, Network & Storage
- Usually Jumbo Frames are required
- What Are Jumbo Frames?
- Jumbo Frames are ethernet frames with more than 1500 bytes of payload. A Jumbo Frame can carry up to 9000 bytes of payload.
- Shared file systems such as Lustre and NFS use Jumbo Frames frequently. HPC applications use a lot of disk I/O and need access to a shared file system, this makes Jumbo Frames critical.
- SR-IOV
- The use of Jumbo Frames is supported on AWS through enhanced networking. Enhanced networking is available using single-root I/O virtualization (SR-IOV) on supported instance types:
- C3
- C4
- D2
- I2
- M4
- R3
- Must be on HVM VMs, not PV
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/enhanced-networking.html
- The use of Jumbo Frames is supported on AWS through enhanced networking. Enhanced networking is available using single-root I/O virtualization (SR-IOV) on supported instance types:
- Placement Groups
A placement group is a logical grouping of instances within a single Availability Zone. Using placement groups enables applications to participate in a low-latency, 10Gbps network. Placement groups are recommended for applications that benefit from low network latency, high network throughput, or both.
To provide the lowest latency and the highest packet-per-second network performance for your placement group, choose an instance type that supports enhanced networking.- Don’t span availability zones: 1 placement group = 1 AZ.
- Placement groups can span subnets, but the subnets must be in the same AZ.
- Only certain instance types (enhanced networking instances) may be launched in to a placement group:
- C3
- C4
- D2
- I2
- M4
- R3
- Existing instances cannot be moved in to a placement group.
- Although launching multiple instance types into a placement group is possible, this reduces the likelihood that the required capacity will be available for your launch to succeed.
- There may not be sufficient capacity to add extra instances later on. It is best practice to size the placement group for the peak load and launch all instances at the same time.
- Exam Tips
- Enhanced Networking is available using single root I/O virtualization (SR-IOV). This requires HVM virtualization.
- A placement group cannot span availability zones, but it can span subnets, provided they are in the same VPC.
- You cannot move existing instances into a placement group.
- Try to use homogenous instance types when launching placement groups.
- Provision your placement group for peak load. You may not be able to add instances later.
- HPC - Guide Lines
ELB
- What is ELB
- Elastic Load Balancing automatically distributes incoming application traffic across multiple Amazon EC2 instances in the cloud.
- It enables you to achieve greater levels of fault tolerance in your applications, seamlessly providing the required amount of load balancing capacity needed to distribute application traffic.
- ELB Tips
- 2 Types of Load Balancers:
- Classic Load Balancer
- Application Load Balancer
- 2 Types of Load Balancers:
- Classic Load Balancer
- High Availability
- You can deploy Classic Load Balancers in either a single or multiple availability zones
- Health Checks
- You can detect the health of Amazon EC2 instances. When a health check detects an unhealthy EC2 instance, it no longer routes traffic to that instance and it will spread the load across the remaining healthy instances.
- Security Features
- When using a VPC, you can create and manage security groups associated with Classic Load Balancers to provide additional networking and security options. You can also create a Classic Load Balancer without a public IP addresses to serve as an internal (non-internet-facing) load balancer.
- SSL Offloading
- You can offload your SSL connections to your classic load balancer. Flexible cipher support allows you to control the ciphers and protocols the load balancer presents to clients.
- Sticky Sessions
- Classic Load Balancers support the ability to stick user sessions to specific EC2 instances using cookies. Traffic will be routed to the same instances as the user continues to access your application.
- IPv6
- Classic Load Balancers support the use of both the Internet Protocol version 4 and 6 (IPv4 an IPv6)
- Layer 4 or Layer 7 Load Balancing
- You can load balance HTTP/HTTPS applications and use layer 7-specific features, such as X-Forwarded and sticky sessions. You can also use strict layer 4 load balancing for applications that rely purely on the TCP protocol.
- Operational Monitoring
- Classic Load Balancer metrics, such as request count and request latency, are reported by Amazon CloudWatch.
- Logging
- You can use the Access Logs feature to record all requests sent to your load balancer, and store the logs in Amazon S3 for later analysis. You can use these logs to diagnose application failures and for analyzing web traffic. You can also use AWS CloudTrail to record classic load balancer API calls for your account and deliver log files to S3. The API call history enables you to perform security analysis, resource change tracking, and compliance auditing.
- High Availability
- Application Load Balancer
- Content-Based Routing
- If your application is composed of several individual services, an Application Load Balancer can route a request to a service based on the content of the request.
- Host-Based Routing
- You can route a client request based on Host field of the HTTP header allowing you to route to multiple domains from the same load balancer.
- Path-based Routing
- You can route a client request based on the URL path of the HTTP header.
- e.g. https://domain.com/uploads vs https://domain.com/downloads
- Containerized Application Support (integrates with ECS)
- HTTP/2 Support
- WebSockets Support
- Native IPv6 Support
- Sticky Sessions
- Health Checks
- High Availability
- Security Features
- Integrates with WAF
- Layer-7 Load Balancing
- HTTPS Support
- Operational Monitoring
- Logging
- Delete Protection
- Request Tracing - custom identifier “X-Amzn-Trace-Id” HTTP header on all requests
- Content-Based Routing
- Classic Load Balancer Tips
- Know which ports ELBs support
- [EC2-VPC] 1-65535
- [EC2-Classic] 25,80,443, 465, 587, 1024-65535
- You cannot assign an Elastic IP address to an Elastic Load Balancer.
- IPv4 & IPv6 is supported.
- You can load balance to the “Zone Apex“ of your domain name.
- Know which ports ELBs support
- ELB Tips
- You can get a history of Elastic Load Balancing API calls made on my account for security analysis and operational troubleshooting purposes by turning on CloudTrail.
- If you have multiple SSL certificates, you should use multiple Elastic Load Balancers, unless you have a wildcard certificate.
- What is ELB
Scaling NATs
- NATs
Instances that you launch into a private subnet in a virtual private cloud (VPC) can’t communicate with the Internet. You can optionally use a network address translation (NAT) instance in a public subnet in your VPC to enable instances in the private subnet to initiate outbound traffic to the Internet, but prevent the instances from receiving inbound traffic initiated by someone on the Internet. - NAT Bottlenecks
Bottlenecks can occur when you have a single NAT that has too much traffic passing through it. There are several approaches to reducing bottlenecks:- Scale Up
- Increase your instance size
- Choose an instance family which supports Enhanced Networking
- Scale Out
- Add an additional NAT & subnet and migrate half your workloads to the new subnet.
- Scale Up
- HA For NATs
You can create HA for NAT instances, but each subnet can only route to 1 NAT at a time. You can fail over a subnet to another NAT.
Good blog on how to do it here: https://aws.amazon.com/cn/articles/high-availability-for-amazon-vpc-nat-instances-an-example/ - Blog On Scaling NATs
Great Blog by Matthew Barlocker: http://nineofclouds.blogspot.com/2013/01/vpc-migration-nats-bandwidth-bottleneck.html
- NATs
Domain 4 Summary
- Domain 4
- Domain 4.0: Network Design for a complex large scale deployment
- 4.1 Demonstrate ability to design and implement networking features of AWS
- 4.2 Demonstrate ability to design and implement connectivity features of AWS
- Direct Connect
- If you are accessing public services using HTTPS endpoints (think DynamoDB, S3) then use public VIFs.
- If you are accessing VPCs using private IP address ranges, then use private VIFs.
- In the US, you only need 1 direct connect connection to connect in to all 4 US regions. Data transferred between regions goes over AWS’s internal lines, not the public internet.
- Direct connect itself is not redundant. You can add redundancy by having 2 connections(2 routes, 2 direct connects), or by having a site-to-site VPN in place.
- Layer 2 connections are not supported.
- Know the difference between a Customer Gateway CGW (Customer side) and Virtual Private Gateway (AWS side.)
- ELB’s
- Know which ports ELBs support
- [EC2-VPC] 1-65535
- [EC2-Classic] 25,80,443, 465, 587, 1024-65535
- You cannot assign an Elastic IP address to an Elastic Load Balancer.
- IPv4 & IPv6 is supported (although VPC’s do not support IPv6 at this time)
- You can load balance to the “Zone Apex“ of your domain name.
- You can get a history of Elastic Load Balancing API calls made on my account for security analysis and operational troubleshooting purposes by turning on CloudTrail.
- If you have multiple SSL certificates, you should use multiple Elastic Load Balancers, unless you have a wildcard certificate.
- Know which ports ELBs support
- HPC & Enhanced Networking
- Enhanced Networking is available using single root I/O virtualization (SR-IOV). This requires HVM virtualization.
- A placement group cannot span availability zones, but it can span subnets, provided they are in the same VPC.
- You cannot move existing instances into a placement group.
- Try to use homogenous instance types when launching placement groups.
- Provision your placement group for peak load. You may not be able to add instances later.
- Scaling NATs
Bottlenecks can occur when you have a single NAT that has too much traffic passing through it. There are several approaches to reducing bottlenecks:- Scale Up
- Increase your instance size
- Choose an instance family which supports Enhanced Networking
- Scale Out
- Add an additional NAT & subnet and migrate half your workloads to the new subnet.
- Scale Up
- VPC Peering
- Create Step
- Owner of the local VPC sends a request to the owner of the second VPC to peer.
- Owner of the second VPC has to accept.
- Owner of the local VPC adds a route to their route table allowing their subnets to route out to the peer VPC
- Owner of the peer VPC adds a route to their route table allowing their subnets to route back to the other VPC.
- Security Groups in both VPCs have to both allow traffic.
- Troubleshooting
- Setting up the peer:
- Are the VPCs in the same region?
- If you can’t create a VPC peer, check to see if the CIDR blocks are overlapping.
- After the peer is setup:
- Check that the relevant security groups and NACLs are allowing traffic through.
- Check that a route has been created in BOTH VPCs routing tables.
- Setting up the peer:
- Create Step
- Domain 4
Domain 5 Data Storage - 15%
- Optimizing S3
- Optimizing For Puts
- Two different types of network scenarios:
- Strong internet connection, with fast speeds (such as fibre.)
- Less reliable internet connection with inconsistent network performance.
- How can we optimize?
- For strong networks, we want to take advantage of the network itself and make the network the bottleneck.
- For weaker networks, we want to prevent large files having to restart their uploads.
- Two different types of network scenarios:
- Parallelizing For PUTs
- By dividing your files in to small parts and then uploading those parts simultaneously, you are “parallelizing“ your puts.
- If 1 part fails, it can be restarted an there are fewer large restarts on an unreliable network.
- Moves the bottleneck to the network itself, which can help increase the aggregate throughput.
- 25-50 MB on high bandwidth networks, and around 10 MB on mobile networks.
- Need to find a balance. Too many increases the connection overhead, too few doesn’t give you any resiliency.
- Optimizing For GETs
- Use CloudFront:
- Multiple Endpoints Globally
- Low Latency
- High Transfer Speeds Available
- Caches Objects from S3
- Two varieties:
- RTMP
- Web Distribution
- Need to use range-based GETs to get multithreaded performance.
- Using the Range HTTP header in a GET request, you can retrieve a specific range of bytes in an object stored in Amazon S3.
- Allows you to send multiple GETs at once, hence parallelizing for GETs.
- Compensates for unreliable network performance.
- Maximizes bandwidth throughput.
- Use CloudFront:
- S3 is Lexicographical
- Introduce some randomness in to the name.
- The more random, the better the performance
- Exam Tips
- Use parallelization to optimize both GETs & PUTs
- S3 stores data in Lexicographical order.
- Introduce randomness to maximize performance.
- Optimizing For Puts
- S3 Best Practices
- Versioning - Recap
- Allows you to protect your files from being accidentally deleted or overwritten.
- No penalty on performance.
- Every time you upload a new file, a new version is created automatically.
- Makes it easy to retrieve deleted versions.
- Makes it easy to roll-back to previous versions.
- Once you turn versioning on, you cannot turn it off – you can only suspend it.
- There are further steps you can take to secure your S3 environment.
- Allows you to protect your files from being accidentally deleted or overwritten.
- Securing S3
- You can use bucket policier to restrict deletes.
- You can also use MFA Delete:
- You have to use two-factor authentication to delete objects permanently.
- You have to use two-factor authentication to change the state of versioning within your bucket.
- Requires both your security credentials, as well as a code from an approved authentication device ( such as Google Authenticator).
- Securing S3 - Use Another Account
- Versioning will protect you on an individual file level.
- Does not protect you against deleting a bucket.
- Bucket deletion could be either malicious or accidental.
- Back your bucket up to another bucket owned by another account using cross account access.
- Exam Tips
- You can secure S3 by:
- Using Bucket Policies
- Using MFA Delete
- Backing Your Bucket Up To Another S3 Bucket Owned By A Separate Account
- You can secure S3 by:
- Versioning - Recap
- Database Design
- Recommended White Paper
- AWS Storage Options
- https://d1.awsstatic.com/whitepapers/Storage/AWS%20Storage%20Services%20Whitepaper-v9.pdf
- Take particular note of the Anti-Patterns for the different technologies.
- Multi-AZ vs Read Replicas
- Multi-AZ
- Used for DR only, not for scaling
- Is synchronous replication
- Read Replicas
- Used for Scaling Out, not DR
- Is Asynchronous replication
- Multi-AZ
- RDS Use Cases
- Amazon RDS is ideal for existing applications that rely on MySQL, Oracle, SQL, PostgreSQL, MariaDB and Aurora.
- Since Amazon RDS offers full compatibility and direct access to native database engines, most code, libraries, and tools designed for these databases should work unmodified with Amazon RDS.
- Amazon RDS is also optimal for new applications with structured data that requires more sophisticated querying and joining capabilities than those provided by Amazon’s NoSQL database offering, Amazon DynamoDB.
- ACID? Think RDS
- The ACID concept is described in ISO/IEC 10026-1:1998 Section 4.
- Atomicity. In a transaction involving two or more discrete pieces of information, either all of the pieces are committed or none are.
- Consistency. A transaction either creates a new and valid state of data, or if any failure occurs, returns all data to its state before the transaction was started.
- Isolation. A transaction in process and not yet committed must remain isolated from any other transaction.
- Durability. Committed data is saved by the system such that, even in the event of a failure and system restart, the data is available in its correct state.
- Where Not To Use RDS
Amazon RDS is a great solution for cloud-based, fully-managed relational databases; but in a number of scenarios, it may not be the right choice.- Index and query-focused data - Many cloud-based solutions don’t require advanced features found in a relational database, such as joins an complex transactions. If your application is more oriented toward indexing and querying data, you may find Amazon DynamoDB to be more appropriate for your needs.
- Numerous BLOBs - While all of the database engines provided by Amazon RDS support binary large objects (BLOBs), if your application makes heavy use of them (audio files, videos, images and so on), you may fin Amazon S3 to be a better choice.
- Automated scalability - Amazon RDS provides pushbutton scaling. If you need fully automated scaling, Amazon DynamoDB may be a better choice.
- Other database platforms - At this time, Amazon RDS provides MySQL, Oracle, SQL Server, PostgreSQL, MariaDB and Aurora databases. If you need another database platform (such as IBM DB2, Informix, or Sybase), you need to deploy a self-managed database on an Amazon EC2 instance by using a relational database AMI, or by installing database software on an Amazon EC2 instance.
- Complete control - If your application requires complete, OS-level control of the database server, with full root or admin login privileges (for example, to install additional third-party software on the same server), a self managed database on Amazon EC2 may be a better match.
- DynamoDB Use Cases
Amazon DynamoDB is ideal for existing or new applications that need a flexible NoSQL database with low read and write latencies, and the ability to scale storage an throughput up or down as needed without code changes or downtime.
Common use cases include: mobile apps, gaming, digital ad serving, live voting and audience interaction for live events, sensor networks, log ingestion, access control for web-based content, metadata storage for Amazon S3 objects, e-commerce shopping carts, and web session management.
Many of these use cases require a highly available and scalable database because downtime or performance degradation has an immediate negative impact on an organization’s business.
Need to automatically scale your database, think DynamoDB. - Where Not To Use DynamoDB
- Prewritten application tied to a traditional relational database - If you are attempting to port an existing application to the AWS cloud, and need to continue using a relational database.
- Joins and/or complex transactions - While many solutions are able to leverage Amazon DynamoDB to support their users, it’s possible that your application may require joins, complex transactions, and other relational infrastructure provided by traditional database platforms. If this is the case, you may want to explore Amazon RDS or Amazon EC2 with a self-managed database.
- Blob Data - If you plan on storing large (greater than 64 KB) BLOB data, such as digital video, images or music, you’ll want to consider Amazon S3. However, Amazon DynamoDB still has a role to play in this scenario, for keeping track of metadata (e.g. item name, size, date created, owner, location and so on) about your binary objects.
- Large data with low I/O rate - Amazon DynamoDB uses SSD drives and is optimized for workloads with a high I/O rate per GB stored. If you plan to store very large amounts of data that are infrequently accessed, other storage options, such as Amazon S3, may be a better choice.
- Exam Tips
- Multi-AZ = Synchronous Replication
- Read Replica = Asynchronous Replication
- RDS is optimal for new applications with structured data that requires more sophisticated querying and joining capabilities
- ACID = RDS
- Don’t use RDS for:
- Index and query-focused data (DynamoDB)
- Numerous BLOBs (S3)
- Automated scalability (DynamoDB)
- Other database platforms such as IBM DB2, Informix, or Sybase (EC2)
- Complete Control (EC2)
- Don’t use DynamoDB for:
- Prewritten application tied to a traditional relational database (RDS)
- Joins and/or complex transactions (RDS)
- Blob Data (S3)
- Large data with low I/O rate (S3)
- Recommended White Paper
- Domain 5
- **Domain 5.0: Data Storage for a complex large scale deployment
- 5.1 Demonstrate ability to make architectural trade off decisions involving storage options
- 5.2 Demonstrate ability to make architectural trade off decisions involving database options
- 5.3 Demonstrate ability to implement the most appropriate data storage architecture
- 5.4 Determine use of synchronous versus asynchronous replication
- Exam Tips
- Read the White Paper!
- AWS Storage Options
- https://d0.awsstatic.com/whitepapers/Storage/aws-storage-options.pdf
- Take particular note of the Anti-Patterns for the different technologies.
- Exam Tips - S3 Performance
- Use parallelization to optimize both GETs & PUTs.
- S3 stores data in Lexicographical order.
- Introduce randomness to maximize performance.
- Exam Tips - Securing S3
- You can secure S3 by:
- Using Bucket Policies
- Using MFA Delete
- Backing Your Bucket Up To Another S3 Bucket Owned By A Separate Account
- You can secure S3 by:
- Exam Tips
- Multi-AZ = Synchronous Replication
- Read Replica = Asynchronous Replication
- RDS is optimal for new applications with structured data that requires more sophisticated querying and joining capabilities
- ACID = RDS
- Don’t use RDS for:
- Index and query-focused data (DynamoDB)
- Numerous BLOBs (S3)
- Automated scalability (DynamoDB)
- Other database platforms such as IBM DB2, Informix, or Sybase (EC2)
- Complete Control (EC2)
- Don’t use DynamoDB for:
- Prewritten application tied to a traditional relational database (RDS)
- Joins and/or complex transactions (RDS)
- Blob Data (S3)
- Large data with low I/O rate (S3)
- **Domain 5.0: Data Storage for a complex large scale deployment
Domain 6 Security - 20%
AWS Directory Services
- AWS Directory Services
AWS Directory Service is a managed service that allows you to connect your AWS resources with an existing on-premises Microsoft Active Directory or to set up a new, stand-alone directory in the AWS cloud.- Comes in 2 flavors:
- AD Connector
- Simple AD
- Comes in 2 flavors:
- AD Connector
AD Connector enables you to easily connect your Microsoft Active Directory to the AWS cloud, without requiring complex directory synchronization technologies or the cost an complexity of hosting a federation infrastructure.
Once set up, your end users and ID administrators can use their existing corporate credentials to log on to AWS applications such as Amazon Workspaces, Amazon WorkDocs or Amazon WorkMail and to manage AWS resources (e.g. Amazon EC2 instances or S3 buckets) via AWS Identity and Access Management (IAM) role-based access to the AWS Management Console.
Your existing security policies, such as password expiration, password history and account lockouts can be enforced consistently – whether users to IT administrators are accessing resources in your on-premises infrastructure or the AWS cloud.
You can also use AD Connector to enable multi-factor authentication by integrating with your existing RADIUS-based MFA infrastructure to provide an additional layer of security when users access AWS applications. - Simple AD
Simple AD is a managed directory which is powered by Samba 4 Active Directory Compatible Server. It supports commonly used features such as user accounts, group memberships, domain-joining Amazon EC2 instances running Linux and Microsoft Windows, as well as Kerberos based single sign-on (SSO), and Group Policies. - Exam Tips
- 2 Types of Directory Services:
- **AD Connector (Used for existing AD Deployments)
- Great way to connect in to existing AD environments.
- Supports MFA
- **Simple AD (Used for new AD Deployments)
- MFA Not Supported
- Cannot add additional AD servers
- No Trust Relationships
- Cannot Transfer FSMO Roles
- **AD Connector (Used for existing AD Deployments)
- 2 Types of Directory Services:
- AWS Directory Services
Security Token Service(STS)
- Security Token Service
- Grants users limited and temporary access to AWS resources. Users can come from three sources:
- Federation (typically Active Directory)
- Uses Security Assertion Markup Language (SAML)
- Grants temporary access based off the users Active Directory credentials. Does not need to be a user in IAM
- Single sign on allows users to log in to AWS console without assigning IAM credentials
- Federation with Mobile Apps
- Use Facebook/Amazon/Google or other OpenID providers to log in
- Cross Account Access
- Let’s users from one AWS account access resources in another
- Understanding The Key Terms
- Federation
- Combining or joining a list of users in one domain (such as IAM) with a list of users in another domain (such as Active Directory, Facebook etc.)
- Identity Broker
- A service that allows you to take an identity from point A and join it (federate it) to point B
- Identity Store
- Services like Active Directory, Facebook, Google etc.
- Identities
- A user of a service like Facebook etc.
- Federation
- Scenario
- AWS blog [AWS Identity and Access Management – Now With Identity Federation]
- You are hosting a company website on some EC2 web servers in your VPC. Users of the website must log in to the site which then authenticates against the companies active directory servers which are based on site at the companies head quarters. Your VPC is connected to your company HQ via a secure IPSEC VPN. Once logged in the user can only have access to their own S3 bucket. How do you set this up?
- Steps of scenario
- Employee enters their username and password
- The application calls an Identity Broker. The broker captures the username and password.
- The Identity Broker uses the organization’s LDAP directory to validate the employee’s identity.
- The Identity Broker calls the new GetFederationToken function using IAM credentials. The call must include an IAM policy and a duration (1 to 36 hours), along with a policy that specifies the permissions to be granted to the temporary security credentials.
- The Security Token Service confirms that the policy of the IAM user making the call to GetFederationToken gives permission to create new tokens and then returns four values to the application: An access key, a secret access key, a token, and a duration (the token’s lifetime).
- The Identity Broker returns the temporary security credentials to the reporting application.
- The data storage application uses the temporary security credentials (including the token) to make requests to Amazon S3.
- Amazon S3 uses IAM to verify that the credentials allow the requested operation on the given S3 bucket and key
- IAM provides S3 with the go-ahead to perform the requested operation.
- In the Exam
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, Then with AWS STS
- Application then gets temporary access to AWS resources
- Scenario 2
- steps of scenario
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, gets an IAM Role associate with a user
- Application then authenticates with STS and assumes that IAM Role
- Application uses that IAM role to interact with S3
- In the Exam
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, Then with AWS STS
- Application then gets temporary access to AWS resources
- steps of scenario
- Security Token Service
Monitoring In The Cloud
- Monitoring
- It’s important to know the difference:
- CloudWatch vs CloudTrail
- Use cases as to where to store your logs
- EBS volumes attached to EC2 instances?
- S3?
- CloudWatch?
- It’s important to know the difference:
- CloudWatch vs CloudTrail
- CloudTrail
CloudTrail enables you to retrieve a history of API calls and other events for all of the regions in your account. This includes calls and events made by the AWS Management Console and command line tools, by any of the AWS SDKs, or by other AWS services.
CloudTrail is used for auditing and collecting a history of API calls made on your environment. It is not a logging service per se. - CloudWatch
- Amazon CloudWatch is a monitoring service for AWS cloud resources and the applications you run on AWS. You can use Amazon CloudWatch to collect and track metrics, collect and monitor log files and set alarms.
- Amazon CloudWatch can monitor AWS resources such as Amazon EC2 instances, Amazon DynamoDB tables, and Amazon RDS DB instances, as well as custom metrics generated by your applications and services, and any log files your applications generate.
- By default, CloudWatch Logs will store your log data indefinitely. You can change the retention for each Log Group at any time.
- CloudWatch Alarm history is only stored for 14 days.
- Billing
Billing for CloudWatch Logging is:
$0.50 per GB ingested per month
$0.03 per GB archived per month
$0.10 per alarm per month
S3 lowest tier is $0.03 per GB. Can be cheaper to store logs in S3 than CloudWatch, but depends on your environment.
- CloudTrail
- Using CloudWatch To Monitor CloudTrail
- One of the ways that you can work with CloudTrail logs is to monitor them in real time by sending them to CloudWatch Logs. For a trail that is enabled in all regions in your account, CloudTrail sends log files from all those regions to a CloudWatch Logs log group.
- You define CloudWatch Logs metric filters that will evaluate your CloudTrail log events for matches in terms, phrases, or values. You assign CloudWatch metrics to the metric filters. You also create CloudWatch alarms that are triggered according to thresholds and time periods that you specify.
- Monitoring
- You can monitor events and ship those logs to:
- CloudWatch
- A Centralized Logging System (AlertLogic, Splunk, SumoLogic)
- S3 (via a script that exports the log files.)
- Avoid storing your logs anywhere that’s not persistent:
- Root device volume on EC2 instance.
- Ephemeral Storage
- Best answers are usually either S3 or CloudWatch
- CloudTrail can be used across multiple accounts in a single S3 bucket.
- CloudWatch now supports Cross Account Subscriptions (Very recent, August 10, 2015) https://aws.amazon.com/about-aws/whats-new/2015/08/amazon-cloudwatch-logs-cross-account-subscriptions/
- You can monitor events and ship those logs to:
- Exam Tips
- CloudWatch for Logs
- CloudTrail for Audits, tracing API calls
- CloudWatch can monitor CloudTrail
- You can send your logs to:
- CloudWatch
- S3
- Third Parties (ALertLogic, SumoLogic, Splunk etc.)
- CloudTrail can log events from multiple accounts to a single S3 bucket.
- CloudWatch supports cross account subscriptions, however this a very new service.
- Always look to store your logs in a persistent & safe place. S3 or CloudWatch are the ideal places.
- By default, CloudWatch Logs will store your log data indefinitely.
- CloudWatch Alarm History is only 14 days.
- Monitoring
Cloud Hardware Security Modules (HSMs)
- What Is A HSM?
- HSM stands for Hardware Security Module, and is a physical device that safeguards and manages digital keys for strong authentication and provides cryptoprocessing. These modules traditionally come in the form of a plug-in card or an external device that attaches directly to a computer or network server.
- Cloud HSMs
- Prior to Cloud, HSM’s customers had to store these devices on premise, introducing a large amount of latency into their environment.
- The AWS CloudHSM service allows you to protect your encryption keys within HSMs designed and validated to government standards for secure key management. You can securely generate, store and manage the cryptographic keys used for data encryption such that they are accessible only by you.
- Cloud HSM - Pricing
- You will be charged an upfront fee for each CloudHSM instance you launch, and an hourly fee for each hour thereafter until you terminate the instance. If you want to try the CloudHSM service for free, you can request a two week trial.
- Now. There are no upfront costs to use AWS CloudHSM. With CloudHSM, you pay an hourly fee for each HSM you launch until you terminate the HSM. https://aws.amazon.com/cloudhsm/pricing/
- You will be charged an upfront fee for each CloudHSM instance you launch, and an hourly fee for each hour thereafter until you terminate the instance. If you want to try the CloudHSM service for free, you can request a two week trial.
- Exam Tips - CloudHSM
- Single Tenanted (1 physical device, for you only)
- Must be used within a VPC
- You can use VPC peering to connect to a CloudHSM
- You can use EBS volume encryption, S3 object encryption and key management with CloudHSM, but this does require custom application scripting.
- If you need fault tolerance, you need to build a cluster, so you will need 2. If you have only one and it fails, you will lose your keys.
- Can integrate with RDS (Oracle & SQL) as well as Redshift
- Monitor via Syslog
- What Is A HSM?
DDOS
- What Is A DDos Attach?
- A Distributed Denial of Service (DDos) attack is an attack that attempts to make your website or application unavailable to your end users.
- This can be achieved by multiple mechanisms, such as large packet floods, by using a combination of reflection and amplification techniques, or by using large botnets.
- Amplification/Reflection Attacks
- Amplification/Reflection attacks can include things such as NTP, SSDP, DNS, Chargen, SNMP attacks etc. and is where an attacker may send a third party server (such as an NTP server) a request using a spoofed IP address. That server will then respond to that request with a greater payload than initial request (usually within the region of 28*54 times larger than the request) to the spoofed IP address.
- This means that if the attacker sends a packet with a spoofed IP address of 64 bytes, the NTP server would respond with up to 3,456 bytes of traffic. Attackers can co-ordinate this and use multiple NTP servers a second to send legitimate NTP traffic to the target.
- Application Attacks (L7)
- Flood of Get request
- Slowloris
- How To Mitigate DDoS?
- Minimize the Attack Surface Area
- Be Ready to Scale to Absorb the Attack
- Safeguard Exposed Resources
- Learn Normal Behavior
- Create a Plan for Attacks
- Minimize The Attack Surface Area
- Some production environments have multiple entry points in to them. Perhaps they allow direct SSH or RDP access to their web servers/application and DB servers for management.
- This can be minimized by using a Bastion/Jump Box that only allows access to specific white list IP addresses to these bastion servers and move the web, application and DB servers to private subnets. By minimizing the attack surface area, you are limiting your exposure to just a few hardened entry points.
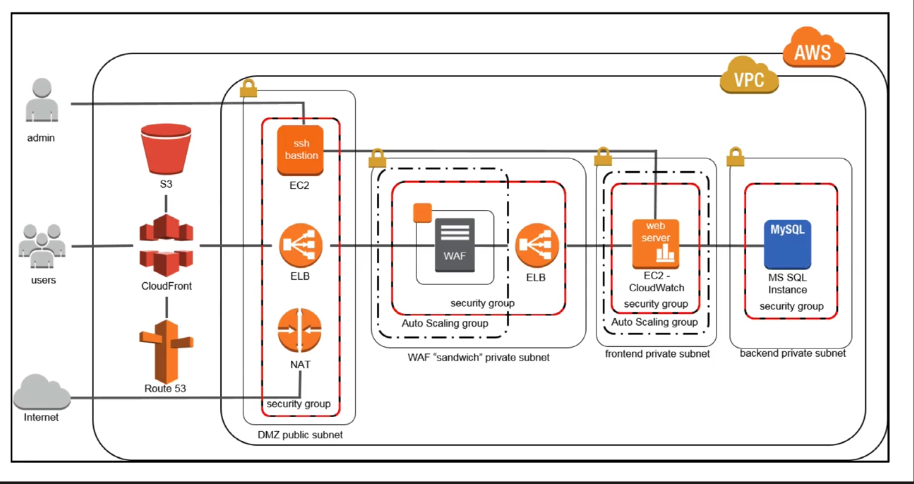
- Be Ready To Scale To Absorb The Attack
- The key strategy behind a DDoS attack is to bring your infrastructure to breaking point. This strategy assumes one thing: that you can’t scale to meet the attack.
- The easiest way to defeat this strategy is to design your infrastructure to scale as, and when, it is needed.
- You can scale both Horizontally & Vertically.
- Scaling Has The Following Benefits
- The attack is spread over a larger area.
- Attackers then have to counter attack, taking up more of their resources.
- Scaling buys you time to analyze the attack and to respond with the appropriate countermeasures.
- Scaling has the added benefit of providing you with additional levels of redundancy.
- Safeguard Exposed Resources
- In situations where you cannot eliminate Internet entry points to your applications, you’ll need to take additional measures to restrict access and protect those entry points without interrupting legitimate en user traffic.
- Three resources that can provide this control and flexibility are Amazon CloudFront, Amazon Route 53 and web application firewalls(WAFs).
- CloudFront:
- Geo Restriction/Blocking – Restrict access to users in specific countries (using whitelists or blacklists).
- Origin Access Identity – Restrict Access to your S3 bucket so that people can only access S3 using CloudFront URLs.
- Route53:
- Alias Record Sets – You can use these to immediately redirect your traffic to an Amazon CloudFront distribution, or to a different ELB load balancer with higher capacity EC2 instances running WAFs or your own security tools. No DNS change, and no need to worry about propagation.
- Private DNS – Allow you to manage internal DNS names for your application resources (web servers, application servers, database etc.) without exposing this information to the public Internet.
- WAFs:
- DDos attacks that happen at the application layer commonly target web applications with lower volumes of traffic compared to infrastructure attacks. To mitigate these types of attacks, you’ll want to include a WAF as port of your infrastructure.
- New WAF Service – You can use the new AWS WAF service.
- AWS Market Place – You can buy other WAF’s on the AWS Market Place.
- DDos attacks that happen at the application layer commonly target web applications with lower volumes of traffic compared to infrastructure attacks. To mitigate these types of attacks, you’ll want to include a WAF as port of your infrastructure.
- CloudFront:
- Learn Normal Behavior
- Be aware of normal and unusual behavior
- Know the different types of traffic and what normal levels of this traffic should be.
- Understand expected and unexpected resource spikes.
- What are the benefits?
- Allows you to spot abnormalities fast.
- You can create alarms to alert you of abnormal behavior.
- Helps you to collect forensic data to understand the attack.
- Be aware of normal and unusual behavior
- Create A Plan For Attacks
- Having a plan in place before an attack ensures that:
- You’ve validated the design of your architecture.
- You understand the costs for your increased resiliency and already know what techniques to employ when you come under attack.
- You know who to contact when an attack happens.
- Having a plan in place before an attack ensures that:
- DDoS Exam Tips
- Definitely worth a few points in the exam.
- Worth reading the white paper: https://d1.awsstatic.com/whitepapers/Security/DDoS_White_Paper.pdf and https://aws.amazon.com/blogs/security/updated-whitepaper-available-aws-best-practices-for-ddos-resiliency/
- Remember the technologies you can use to mitigate a DDoS attack:
- CloudFront
- Route53
- ELB’s
- WAFs
- Autoscaling (Use for both WAFs an Web Servers)
- CloudWatch
- What Is A DDos Attach?
IDS & IPS
- What Is IDS?
- An Intrusion Detection System (IDS) inspects all inbound and outbound network activity and identifies suspicious patterns that may indicate a network or system attack from someone attempting to break into, or compromise, a system.
- What Is IPS?
- An Intrusion Prevention System (IPS) is a network security/threat prevention technology that examines network traffic flows to detect and prevent vulnerability exploits.
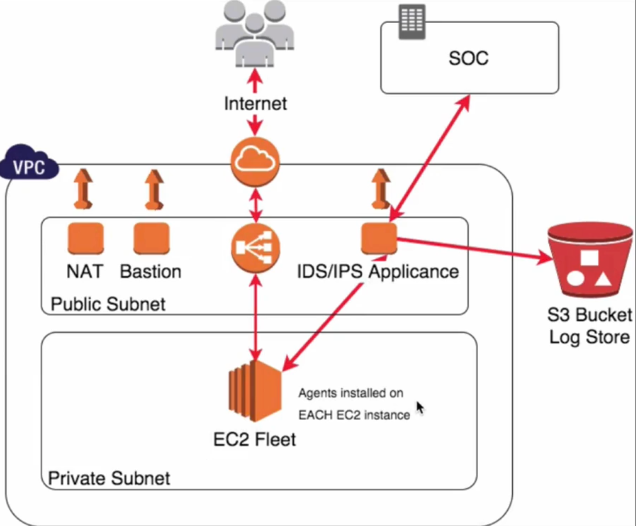
- An Intrusion Prevention System (IPS) is a network security/threat prevention technology that examines network traffic flows to detect and prevent vulnerability exploits.
- IDS/IPS Exam Tips
- IDS is intrusion Detection.
- IPS is intrusion Prevention.
- Generally, you have an appliance in a public subnet, and then agents installed on each EC2 instance.
- Log files can be sent to a SOC (Security Operation Centre) or stored in S3.
- Great Youtube Video
- https://www.youtube.com/watch?v=wZ8sB7hfyvw
- AltertLogic Threat Manager AWS Youtube.
- What Is IDS?
Domain 6 - Summary
- Domain 6
- Domain 6.0: Security
- 6.1 Design information security management systems and compliance controls
- 6.2 Design security controls with the AWS shared responsibility model and global infrastructure
- 6.3 Design identity and access management controls
- 6.4 Design protection of Data at Rest controls
- 6.5 Design protection of Data in Flight and Network Perimeter controls
- Worth 20%
- Domain 6.0: Security
- Exam Tips - CloudHSM
- Single Tenanted (1 physical device, for you only)
- Must be used within a VPC
- You can use VPC peering to connect to a CloudHSM
- You can use EBS volume encryption, S3 object encryption and key management with CloudHSM, but this does require custom application scripting.
- If you need fault tolerance, you need to build a cluster, so you will need 2. If you have only one and it fails, you will lose your keys.
- Can integrate with RDS (Oracle & SQL) as well as Redshift
- Monitor via Syslog
- Directory Services - Exam Tips
- 2 Types of Directory Services:
- AD Connector (Used for existing AD Deployments)
- Great way to connect in to existing AD environments.
- Supports MFA
- Simple AD (Used for new AD Deployments)
- MFA Not Supported
- Cannot add additional AD servers
- No Trust Relationships
- Cannot Transfer FSMO Roles
- AD Connector (Used for existing AD Deployments)
- 2 Types of Directory Services:
- IDS/IPS Exam Tips
- IDS is intrusion Detection.
- IPS is intrusion Prevention.
- Generally, you have an appliance in a public subnet, and then agents installed on each EC2 instance.
- Log files can be sent to a SOC (Security Operation Centre) or stored in S3.
- Monitoring Exam Tips
- CloudWatch for Logs
- CloudTrail for Audits, tracing API calls
- CloudWatch can monitor CloudTrail
- You can send your logs to:
- CloudWatch
- S3
- Third Parties (ALertLogic, SumoLogic, Splunk etc.)
- CloudTrail can log events from multiple accounts to a single S3 bucket.
- CloudWatch supports cross account subscriptions, however this a very new service.
- Always look to store your logs in a persistent & safe place. S3 or CloudWatch are the ideal places.
- By default, CloudWatch Logs will store your log data indefinitely.
- CloudWatch Alarm History is only 14 days.
- Identity Brokers
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, Then with AWS STS
- Application then gets temporary access to AWS resources
- Domain 6
Domain 7 - Scalability & Elasticity - 15%
CloudFront
- CloudFront
Amazon CloudFront can be used to deliver your entire website, including dynamic, static, streaming, and interactive content using a global network of edge locations.
Requests for your content are automatically routed to the nearest edge location, so content is delivered with the best possible performance. Amazon CloudFront is optimized to work with other Amazon Web Services, like S3, EC2, ELB and Route 53. - Key Concepts
- Distribution Types
- Geo Restriction
- Support for POST, PUT & Other HTTP Methods
- SSL Configurations
- Wildcard CNAME support
- Invalidation
- Zone Apex Support
- Edge Caching
- Distribution Types
- Two types of Distributions:
- Web Distributions
- RTMP Distributions
- Two types of Distributions:
- Geo Restriction
- Geo Restriction or Geoblocking lets you choose the countries in which you want to restrict access to your content
- Whitelists or Blacklists particular countries
- Can be done either using the API or the console
- Viewer from blacklisted countries will see a HTTP 403 error
- You can also create custom error pages
- Support For
- GET, HEAD, POST, PUT, PATCH, DELETE and OPTIONS.
- Amazon CloudFront does not cache the responses to POST, PUT, DELETE and PATCH requests – these requests are proxied back to the origin server.
- SSL
You can use either HTTP or HTTPS with CloudFront. With SSL, you can use the default CloudFront URL, or your own custom URL with your own SSL certificate.- Dedicated IP Custom SSL: Allocates dedicated IP addresses to serve your SSL content at each CloudFront edge location. VERY Expensive. $600 USD per certificate per month. However will support older browsers.
- SNI Custom SSL: Relies on the SNI extension of the Transport Layer Security protocol, which allows multiple domains to serve SSL traffic over the same IP address by including the hostname viewers are trying to connect to. Older browsers won’t support it.
- CNAME Support
- CNAMEs are supported
- You can have 10 CNAMES aliases to each distribution.
- CloudFront also supports wildcard CNAMEs.
- CNAMEs are supported
- Invalidation Requests
There are multiple options for removing a file from the edge locations. You can simply delete the file from your origin and, as content in the edge locations reaches the expiration period defined in each object’s HTTP header, it will be removed.
In the event that offensive or potentially harmful material needs to be removed before the specified expiration time, you can use the Invalidation API to remove the object from all Amazon CloudFront edge locations. - Zone Apex Support
Using Amazon Route S3, AWS’s authoritative DNS service, you can configure an ‘Alias‘ record that lets you map the apex or root (example.com) of your DNS name to your Amazon CloudFront distribution.
http://example.com => http://d1111eft.cloufront.net
Amazon Route 53 will then respond to each request for an Alias record with the right IP address(es) for your CloudFront distribution. Route 53 doesn’t charge for queries to Alias records that are mapped to a CloudFront distribution. - Dynamic Content Support
Amazon CloudFront supports delivery of dynamic content that is customized or personalized using HTTP cookies. To use this feature, you specify whether you want Amazon CloudFront to forward some or all of your cookies to your custom origin server. Amazon CloudFront then considers the forwarded cookie values when identifying a unique object in its cache.
This way, your end users get both the benefit of content that is personalized just for them with a cookie and the performance benefits of Amazon CloudFront. You can also optionally choose to log the cookie values in Amazon CloudFront access logs. - Exam Tips - CloudFront
- 2 distribution types: Web & RTMP
- You can use Geo Restriction to white list or black list a country.
- You can use SSL with CloudFront. You can either use the default URL or your own custom URL. If you use custom URL you can use Dedicated IP Custom SSL or SNI Custom SSL.
- CloudFront Supports GET, HEAD, POST, PUT, PATCH, DELETE and OPTIONS.
- Amazon CloudFront does not cache the responses to POST, PUT, DELETE and PATCH requests – these requests are proxied back to the origin server.
- CNAMES are supported
- In the event that offensive or potentially harmful material needs to be removed before the specified expiration time, you can use the Invalidation API to remove the object from all Amazon CloudFront edge locations. This is called an invalidation request.
- Zone Apex records are supported if you use Route53. This is achieved by using an Alias record.
- Dynamic Content is supported! Amazon CloudFront supports delivery of dynamic content that is customized or personalized using HTTP cookies.
- CloudFront
Memcached vs Redis
- Memcached vs Redis
In the SA Pro exam, you will be given a number of different scenarios. In some of these you will need to decide which ElastiCache Engine you need to use. ElastiCache has two different engines: Memcached & Redis.
Memcached and Redis look similar on the surface: both are in-memory key stores. However, in practice, there are significant differences. - Requirement in Memcached and Redis
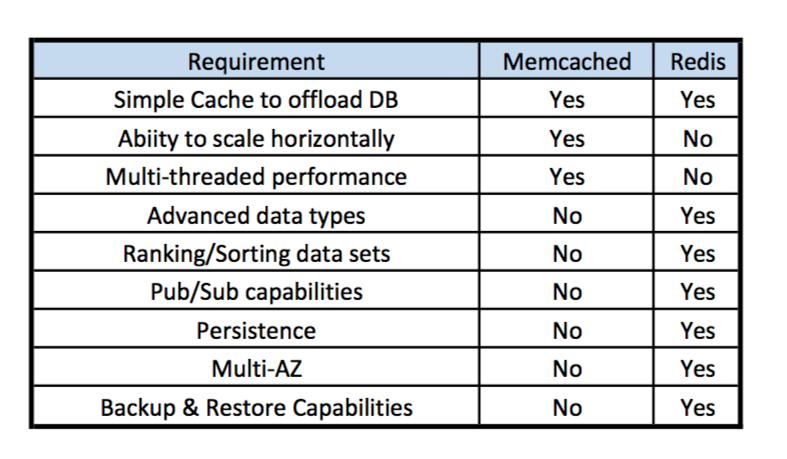
- Exam Tips - Use Memcached If …
- You want the simplest model possible.
- You need to run large nodes with multiple cores or threads.
- You need the ability to scale out, adding and removing nodes as demand on your system increases and decreases.
- You want to shard your data across multiple nodes.
- You need to cache objects, such as a database.
- Exam Tips - Use Redis If…
- You need complex data types, such as strings, hashed, lists and sets.
- You need to sort or rank in-memory data-sets.
- You want persistence of your key store.
- You want to replicate your data from the primary to one or more read replicas for availability.
- You need automatic failover if any of your primary nodes fail.
- You want publish and subscribe (pub/sub) capabilities – the client being informed of events on the server.
- You want backup and restore capabilities.
- Memcached vs Redis
Kinesis
- Kinesis
Kinesis can be involved in many different scenario questions and you need to have a good understanding of what Kinesis is, what the different components are, and where you should use Kinesis. - What Is Kinesis?
Amazon Kinesis Streams enable you to build custom applications that process or analyze streaming data for specialized needs. You can continuously add various types of data, such as clickstreams, application logs, and social media to an Amazon Kinesis stream from hundreds of thousands of sources. Within seconds, the data will be available for your Amazon Kinesis Applications to read and process from the stream.
Data in Kinesis is stored for 24 hours by default. You can increase this to 7 days if required.
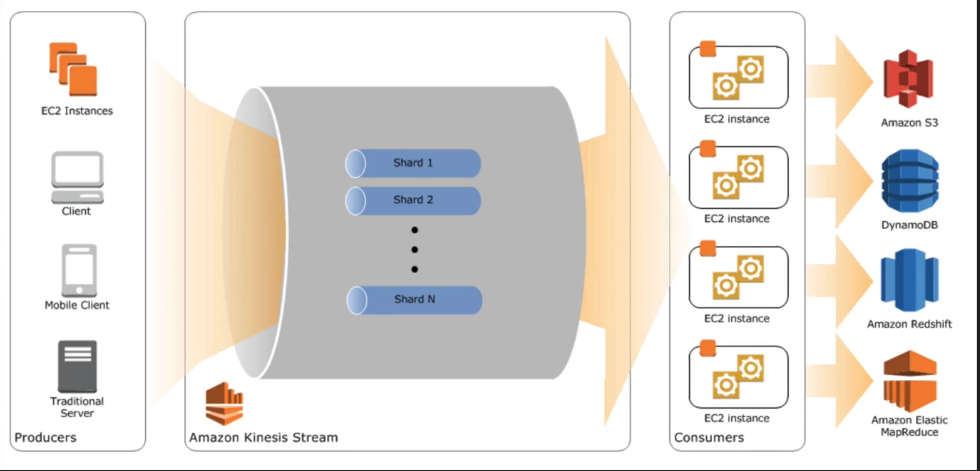
- Key Concepts
- Data Producers
- Shards
- Records
- Sequence Number
- Partition Key
- Data Itself (Blob)
- Data Consumers (Kinesis Streams Applications)
- Data Producers
- Amazon Kinesis Streams API
- PutRecord (Single data record)
- PutRecords (Multiple data records)
- Amazon Kinesis Producer Library (KPL)
- On Github, By using the KPL, customers do not need to develop the same logic every time they create a new application for data ingestion.
- Amazon Kinesis Agent
- Prebuilt Java Application you can install on your linux devices.
- Amazon Kinesis Streams API
- What Is A Shard?
A Shard is simply the unit of measurement of data when referring to Kinesis.
One shard provides a capacity of 1MB/sec data input and 2MB/sec data output. One shard can support up to 1000 PUT records per second. You will specify the number of shards needed when you create a stream. For example, you can create a stream with two shards. This stream has a throughput of 2MB/sec data input and 4MB/sec data output, and allows up to 2000 PUT records per second. You can dynamically add or remove shards from your stream as your data throughput changes via resharding. - What Is A Partition Key?
Kinesis Streams can consist of many different shards. You can group the data by shard by using a partition key.
Essentially, the partition key tells you which shard the data belongs to. A partition key is specified by the applications putting the data into a stream. - What Is A Sequence Number?
Each data record has a unique sequence number. Think of it as a unique key.
The sequence number is assigned by Streams after you write to the stream with client.putRecord or client.putRecords.
You can’t use sequence numbers to logically separate data in terms of what shards they have come from - you can only do this using partition keys. - Blobs
- Data blobs are the data your data producer adds to a stream. The maximum size of a data blob (the data payload after Base64-decoding) is 1 megabyte (MB).
- Exam Tips - Kinesis
- Any kind of scenario where you are streaming large amounts of data that need to be processed quickly, think Kinesis.
- Concepts
- Data Producers
- Shards
- Records
- Sequence Number
- Partition Key
- Data Itself (Blob)
- Data Consumers (Kinesis Streams Applications)
- Data is stored for 24 hours by default within streams and can be increased to 7 days.
- Use S3, Redshift etc. to store processed data for longer term. Kinesis streams IS NOT PERSISTENT storage.
- Kinesis
SNS Mobile Push
- SNS Mobile Push
- A topic that can come up a fair bit in the various different scenarios. You send push notification messages to both mobile devices and desktops using one of the following supported push notification services:
- Amazon Device Messaging (ADM)
- Apple Push Notification Service (APNS) for both iOS and Mac OS X
- Baidu Cloud Push (Baidu)
- Google Cloud Messaging for Android (GCM)
- Microsoft Push Notification Service for Windows Phone (MPNS)
- Windows Push Notification Services (WNS)
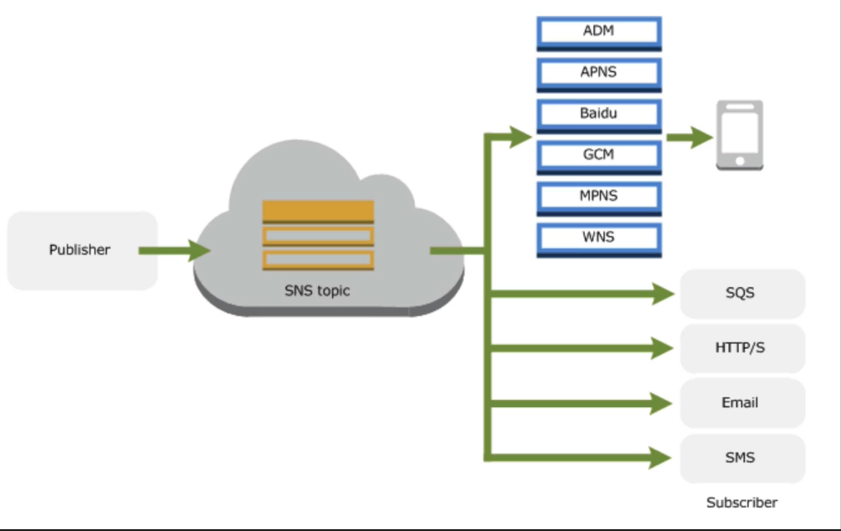
- A topic that can come up a fair bit in the various different scenarios. You send push notification messages to both mobile devices and desktops using one of the following supported push notification services:
- Steps
- Request Credentials from Mobile Platforms
- Request Token from Mobile Platforms
- Create Platform Application Object
- Create Platform Endpoint Object
- Publish Message to Mobile Endpoint
- Further reading:
- Exam Tips - SNS Mobile Push
- You can extend SNS to mobile applications using SNS Mobile Push. The following push notifications are supported:
- Amazon Device Messaging (ADM)
- Apple Push Notification Service (APNS) for both iOS and Mac OS X
- Baidu Cloud Push (Baidu)
- Google Cloud Messaging for Android (GCM)
- Microsoft Push Notification Service for Windows Phone (MPNS)
- Windows Push Notification Services (WNS)
- You can extend SNS to mobile applications using SNS Mobile Push. The following push notifications are supported:
- SNS Mobile Push
Domain 7
- Domain 7.0 - Scalability & Elasticity
- 7.1 Demonstrate the ability to design a loosely coupled system
- 7.2 Demonstrate ability to implement the most appropriate front-end scaling architecture
- 7.3 Demonstrate ability to implement the most appropriate middle-tier scaling architecture
- 7.4 Demonstrate ability to implement the most appropriate data storage scaling architecture
- 7.5 Determine trade-offs between vertical and horizontal scaling
- Exam Tips - CloudFront
- 2 distribution types: Web & RTMP
- You can use Geo Restriction to white list or black list a country.
- You can use SSL with CloudFront. You can either use the default URL or your own custom URL. If you use custom URL you can use Dedicated IP Custom SSL or SNI Custom SSL.
- CloudFront Supports GET, HEAD, POST, PUT, PATCH, DELETE and OPTIONS.
- Amazon CloudFront does not cache the responses to POST, PUT, DELETE and PATCH requests – these requests are proxied back to the origin server.
- CNAMES are supported
- In the event that offensive or potentially harmful material needs to be removed before the specified expiration time, you can use the Invalidation API to remove the object from all Amazon CloudFront edge locations. This is called an invalidation request.
- Zone Apex records are supported if you use Route53. This is achieved by using an Alias record.
- Dynamic Content is supported! Amazon CloudFront supports delivery of dynamic content that is customized or personalized using HTTP cookies.
- Exam Tips - Use Memcached If …
- You want the simplest model possible.
- You need to run large nodes with multiple cores or threads.
- You need the ability to scale out, adding and removing nodes as demand on your system increases and decreases.
- You want to shard your data across multiple nodes.
- You need to cache objects, such as a database.
- Exam Tips - Use Redis If…
- You need complex data types, such as strings, hashed, lists and sets.
- You need to sort or rank in-memory data-sets.
- You want persistence of your key store.
- You want to replicate your data from the primary to one or more read replicas for availability.
- You need automatic failover if any of your primary nodes fail.
- You want publish and subscribe (pub/sub) capabilities – the client being informed of events on the server.
- You want backup and restore capabilities.
- Exam Tips - SNS Mobile Push
- You can extend SNS to mobile applications using SNS Mobile Push. The following push notifications are supported:
- Amazon Device Messaging (ADM)
- Apple Push Notification Service (APNS) for both iOS and Mac OS X
- Baidu Cloud Push (Baidu)
- Google Cloud Messaging for Android (GCM)
- Microsoft Push Notification Service for Windows Phone (MPNS)
- Windows Push Notification Services (WNS)
- You can extend SNS to mobile applications using SNS Mobile Push. The following push notifications are supported:
- Exam Tips - Kinesis
- Any kind of scenario where you are streaming large amounts of data that need to be processed quickly, think Kinesis.
- Concepts
- Data Producers
- Shards
- Records
- Sequence Number
- Partition Key
- Data Itself (Blob)
- Data Consumers (Kinesis Streams Applications)
- Data is stored for 24 hours by default within streams and can be increased to 7 days.
- Use S3, Redshift etc. to store processed data for longer term. Kinesis streams IS NOT PERSISTENT storage.
- Domain 7.0 - Scalability & Elasticity
Domain 8 - Cloud Migration & Hybrid Architecture - 10%
- Vmware Migrations
- Migrations
- AWS Management Portal for vCenter enables you to manage your AWS resources using VMware vCenter.
- The portal installs as a vCenter plug-in within your existing vCenter environment. Once installed, it enables you to migrate VMware VMs to Amazon EC2 and manage AWS resources from within vCenter.
- Common Use Cases
- Migrate VMware VMs to Amazon EC2
- Reach New Geographies from vCenter
- Self-Service AWS Portal within vCenter
- Leverage vCenter Experience While Getting Started with AWS
- Product Demo
- Exam Tips - VMware
- vCenter has a plug-in that it enables you to migrate VMware VMs to Amazon EC2 and manage AWS resources from within vCenter.
- Use Cases Include:
- Migrate VMware VMs to Amazon EC2
- Reach New Geographies from vCenter
- Self-Server AWS Portal within vCenter
- Leverage vCenter Experience While Getting Started with AWS
- Migrations
- Storage Gateway
- Storage Gateway
- Gateway-Cached Volumes
- iSCSI based block storage
- Gateway-Stored Volumes
- iSCSI based block storage
- Gateway-Virtual Tape Library
- iSCSI based virtual tape solution
- Gateway-Cached Volumes
- Storage Gateway Migrations
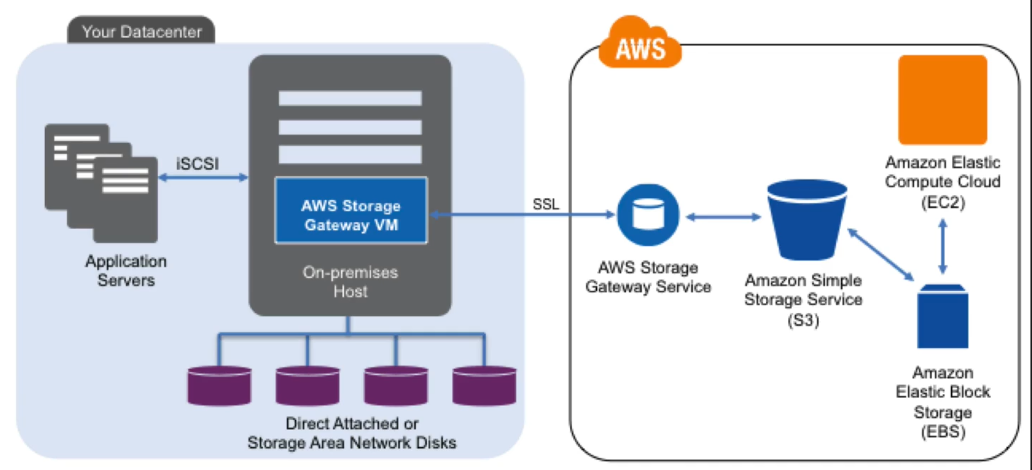
- Consistent Snapshots
- Snapshots provide a point-in-time view of data that has been written to your AWS Storage Gateway volumes. However, snapshots only capture data that has been written to your storage volumes, which can exclude data that has been buffered by either the client or OS.
- Your application and operating system will eventually flush this buffered data to your storage volumes.
- If you need to guarantee that your operating system and file system have flushed their buffered data to disk prior to taking a snapshot, you can do this by taking your storage volume offline before taking a snapshot.
- Doing this forces your operating system to flush its data to disk. After the snapshot is complete. you can bring the volume back online.
- Exam Tips
- You can use Storage Gateway to migrate your existing VMs to AWS.
- You need to ensure that the snapshots are consistent. The best way to do this is to your VM offline and then do the snapshot.
- Storage Gateway
- Data Pipeline
- Data Pipeline
- AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premise data sources, at specified intervals.
- Data Pipeline - Key Concepts
- Pipeline
- Datanode
- Activity
- Procondition
- Schedule
- Pipeline
- Pipeline
- A pipeline is simply the name of the container that contains the datanodes, activities, preconditions, and schedules required in order to move your data from one location to another.
- A pipeline can run either on an EC2 instance or an EMR instance.
- Data Pipeline will provision and terminate these resources for you automatically.
- Pipeline
- Data Pipeline - Use on Premise
- Pipeline - On Premise
- AWS Data Pipeline supplies a Task Runner package that can be installed on your on-premise hosts. This package continuously polls the AWS Data Pipeline service for work to perform. When it’s time to run a particular activity on your on-premise resources, for example, executing a DB stored procedure or a database dump, AWS Data Pipeline will issue the appropriate command to the Task Runner.
- Pipeline - On Premise
- Data Pipeline - Data Nodes
- DataNode
- A data node is essentially the end destination for your data. For example, a data node can reference a specific Amazon S3 path. AWS Data Pipeline supports an expression language that makes it easy to reference data which is generated on a regular basis. For example, you could specify that your Amazon S3 data format is s3://example-bucket/my-logs/logdata-#{scheduledStartTime(‘YYYY-MM-dd-HH’)}.tgz.
- DataNode
- Data Pipeline - Activity
- Activity
- An activity is an action that AWS Data Pipeline initiates on your behalf as part of a pipeline. Example activities are EMR or Hive jobs, copies, SQL queries, or command-line scripts.
- You can specify your own custom activities using the ShellCommandActivity
- Activity
- Data Pipeline - Precondition
- Precondition
- A precondition is a readiness check that can be optionally associated with a data source or activity. If a data source has a precondition check, then that check must complete successfully before any activities consuming the data source are launched. If an activity has a precondition, then the precondition check must complete successfully before the activity is run. This can be useful if you are running an activity that is expensive to compute, and should not run until specific criteria are met.
- You can specify custom preconditions.
- Precondition
- DynamoDBDataExists - Does data exist?
- DynamoDBTableExists - Does Table exist?
- S3KeyExists - Does S3 path Exist?
- S3PrefixExists - Does a file exist within that S3 path?
- ShellCommandPrecondition - Custom Preconditions
- Precondition
- Data Pipeline - Schedule
- Schedule
- Schedules define when your pipeline activities run and the frequency with which the service expects your data to be available.
- Schedule
- Exam Tips - Data Pipeline
- AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services.
- Can be integrated with on-premise environments.
- Can be scheduled.
- Data Pipeline will provision and terminate resources as, and when, required.
- A lot of its functionality has been replaced by Lambda.
- A Pipeline consists of:
- Datanode
- Activity
- Precondition
- Schedule
- Data Pipeline
- Migrations & Networking
- CIDR Reservations
- When you create a subnet, you specify the CIDR block for the subnet. The allowed block size is between a /28 netmask and /16 netmask.
- If you create more than one subnet in a VPC, the CIDR blocks of the subnets must not overlap.
- The first four IP addresses and the last IP address in each subnet CIDR block are not available for you to use, and cannot be assigned to an instance. For example, in a subnet with CIDR block 10.0.0.0/24, the following 5 IP addresses are reserved:
- 10.0.0.0: Network address.
- 10.0.0.1: Reserved by AWS for the VPC router.
- 10.0.0.2: Reserved by AWS for mapping to the Amazon-Provided DNS.
- 10.0.0.3: Reserved by AWS for future use.
- 10.0.0.255: Network broadcast address. AWS do not support broadcast in a VPC; therefore they reserve this address.
- VPN To Direct Connect Migrations
- Most organizations will have a site-to-site VPN tunnel from their location to AWS. As traffic begins to become heavier, organizations will opt to use Direct Connect.
- Once Direct Connect is installed, you should configure it so that your VPN connection & your Direct Connect connection are within the same BGP community. You then configure BGP so that your VPN connection has a higher cost than the Direct Connect connection.
- Exam Tips - Network & Migrations
- CIDR blocks can be between /16 - /28
- AWS reserve 5 IP addresses per CIDR block.
- You can migrate from a VPN connection to a Direct Connect connection by using BGP. Simply ensure that the VPN connection has a higher BGP cost than the Direct Connect connection.
- CIDR Reservations
- Domain 8 - Summary
- Domain 8 - Cloud Migration & Hybrid Architecture
- Domain 8.0: Cloud Migration and Hybrid Architecture
- 8.1 Plan and execute for applications migrations
- 8.2 Demonstrate ability to design hybrid cloud architectures
- Worth 10%
- Domain 8.0: Cloud Migration and Hybrid Architecture
- Exam Tips - VMware
- vCenter has a plug-in that it enables you to migrate VMware VMs to Amazon EC2 and manage AWS resources from within vCenter.
- Use Cases Include:
- Migrate VMware VMs to Amazon EC2
- Reach New Geographies from vCenter
- Self-Server AWS Portal within vCenter
- Leverage vCenter Experience While Getting Started with AWS
- Exam Tips - Storage Gateway Migrations
- You can use Storage Gateway to migrate your existing VMs to AWS.
- You need to ensure that the snapshots are consistent. The best way to do this is to your VM offline and then do the snapshot.
- Exam Tips - Data Pipeline
- AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services.
- Can be integrated with on-premise environments.
- Can be scheduled.
- Data Pipeline will provision and terminate resources as, and when, required.
- A lot of its functionality has been replaced by Lambda.
- A Pipeline consists of:
- Datanode
- Activity
- Precondition
- Schedule
- Exam Tips - Network & Migrations
- CIDR blocks can be between /16 - /28
- AWS reserve 5 IP addresses per CIDR block.
- You can migrate from a VPN connection to a Direct Connect connection by using BGP. Simply ensure that the VPN connection has a higher BGP cost than the Direct Connect connection.
- Domain 8 - Cloud Migration & Hybrid Architecture
Additional Content
CloudFront
- CloudFront Origin Access Identity (OAI)
- used to restrict access to S3 content https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-restricting-access-to-s3.html
- 注意点: 做实验时,如果设置好后,发现不能通过cloudFront的节点来访问S3的内容。要注意看一下浏览器的url,当你通过cloudfront节点访问S3资源的时,有没有被redirect到S3的url去,如果有,就说明cloudfront设置还没有完全生效,隔一段时间后再试就会发现没有问题了
- 官方论坛里面提及了,在CloudFront使用了新建立的bucket时会可能出现有这个问题,因为新Bucket的domian还没有完全扩散出去 Cloudfront domain redirects to S3 Origin URL
- 详细的操作步骤 – AWS CloudFront access denied to S3 bucket
- CloudFront redirecting to origin?
- Custom SSL Certificate
- use SSL Certificate stored in AWS Certificate Manager (ACM) in the US East(N. Virginia) Region
- use a certificate stored in IAM.
- Custom SSL Options for Amazon CloudFront - https://aws.amazon.com/cloudfront/custom-ssl-domains/
- SNI Custom SSL - SNI (Server Name Indication)
- Dedicated IP Custom SSL
- Why set TTL to 0
- https://aws.amazon.com/blogs/aws/amazon-cloudfront-support-for-dynamic-content/
- In many cases, dynamic content is either not cacheable or cacheable for a very short period of time, perhaps just a few seconds. In the past, CloudFront’s minimum TTL was 60 minutes since all content was considered static. The new minimum TTL value is 0 seconds. If you set the TTL for a particular origin to 0, CloudFront will still cache the content from that origin. It will then make a GET request with an If-Modified-Since header, thereby giving the origin a chance to signal that CloudFront can continue to use the cached content if it hasn’t changed at the origin.
- CloudFront Origin Access Identity (OAI)
RedShift
- RedShift workload Management(WLM)
- enables users to manage priorities flexibly within workloads so that short, fast-running queries won’t get stuck in queues behind long-running queries.
- Copying Snapshots to Another Region – https://docs.aws.amazon.com/redshift/latest/mgmt/working-with-snapshots.html
- You can configure Amazon Redshift to automatically copy snapshots (automated or manual) for a cluster to another region
- RedShift workload Management(WLM)
NAT
- High Available NAT
- Good blog on how to do it here: https://aws.amazon.com/cn/articles/high-availability-for-amazon-vpc-nat-instances-an-example/
- High Available NAT
WAF
- WAF sandwich
Multicast
- Multicast is not available on AWS
- You can create a virtual overlay network that runs on the OS level of the instance https://aws.amazon.com/articles/overlay-multicast-in-amazon-virtual-private-cloud/
EC2
- RAID https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/raid-config.html
- RAID 0 - 增加吞吐量但是不提供冗余
- RAID 1 - 增加冗余,但是不增加吞吐量
- ec2:RunInstances
- Policy中如果RunInstances的Resource只有“arn:aws:ec2:us-east-1:accountid:instance/*”的话,是不能获得新建Instance的权限的
- 因为新建Instance需要涉及到很多资源, 还需要”key-pair/“,”security-group/“,volume, ami,subnet, network-interface等等
- How to increase throughput of the instance bandwidth
- Enhanced networking uses single root I/O virtualization (SR-IOV) to provide high-performance networking capabilities on supported instance types. SR-IOV is a method of device virtualization that provides higher I/O performance and lower CPU utilization when compared to traditional virtualized network interfaces. Enhanced networking provides higher bandwidth, higher packet per second (PPS) performance, and consistently lower inter-instance latencies.
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/enhanced-networking.html
- RAID https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/raid-config.html
Identity Broker
- Assume Role - AssumeRole
- GetFederationToken -
CloudWatch
- DashBoard
- You can monitor AWS resources in multiple regions using a single CloudWatch dashboard.
- select the region and add the metric to dashboard, it can be shown in other region
- DashBoard
IAM
- SAML
- Revoking IAM Role Temporary Security Credential
IPSec
- advantage of an IPSec
- Data encryption across the internet
- Protection of data in transit over the Internet
- Peer identity authentication between source and destination (in AWS that is the VPN gateway and customer gateway)
- Data integrity protection across the Internet
- advantage of an IPSec
Kinesis
- What can I do with Amazon Kinesis Data Streams - https://aws.amazon.com/kinesis/data-streams/faqs/
- Accelerated log and data feed intake: Instead of waiting to batch up the data, you can have your data producers push data to an Amazon Kinesis data stream as soon as the data is produced, preventing data loss in case of data producer failures. For example, system and application logs can be continuously added to a data stream and be available for processing within seconds.
- Real-time metrics and reporting: You can extract metrics and generate reports from Amazon Kinesis data stream data in real-time. For example, your Amazon Kinesis Application can work on metrics and reporting for system and application logs as the data is streaming in, rather than wait to receive data batches.
- Real-time data analytics: With Amazon Kinesis Data Streams, you can run real-time streaming data analytics. For example, you can add clickstreams to your Amazon Kinesis data stream and have your Amazon Kinesis Application run analytics in real-time, enabling you to gain insights out of your data at a scale of minutes instead of hours or days.
- Complex stream processing: You can create Directed Acyclic Graphs (DAGs) of Amazon Kinesis Applications and data streams. In this scenario, one or more Amazon Kinesis Applications can add data to another Amazon Kinesis data stream for further processing, enabling successive stages of stream processing.
- What can I do with Amazon Kinesis Data Streams - https://aws.amazon.com/kinesis/data-streams/faqs/
OpsWorks
- AWS OpsWorks Stacks Lifecycle Events
- Setup
- Configure
- Deploy
- Undeploy
- Shutdown
- AWS OpsWorks Stacks Lifecycle Events
Direct Connect
- AWS re:Invent video about DX in 2016 and 2017
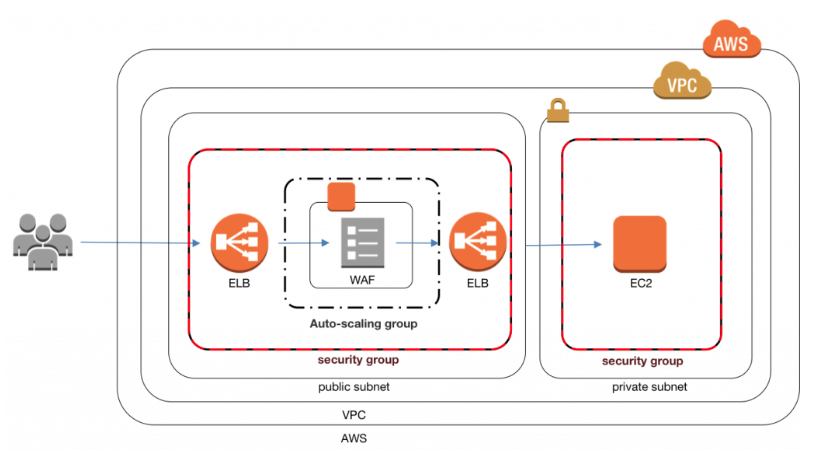
Whitepaper
- https://d1.awsstatic.com/whitepapers/Security/DDoS_White_Paper.pdf
- https://aws.amazon.com/blogs/security/how-to-configure-rate-based-blacklisting-with-aws-waf-and-aws-lambda/
- https://aws.amazon.com/blogs/security/how-to-automatically-update-your-security-groups-for-amazon-cloudfront-and-aws-waf-by-using-aws-lambda/
- Subscribe to AWS Public IP Address Changes via Amazon SNS
- AmazonIpSpaceChanged的Topic是在us-ease-1中的,所以订阅这个Topic的时候,必须切换到N.Virginia才能订阅, 就像Billing Alarm只能在N.Virginia中设置一样