AWS Certified Sysops Administrator - Associate Road Map
Official AWS Certification Page
- 参加 AWS 培训课程
- 查看考试指南和样题
- 了解考试涉及的概念并整体了解需要学习哪些内容, AWS Certified SysOps Administrator - Associate 考试指南 相当于考试大纲, 必看,而且需要反复的看。因为学习过一阵后再来看Guide,会有更深的体会。
- 考试样题用于熟悉题目题型
- 完成自主进度动手实验和备考任务
- 官方qwikLABS 任务提供了一系列动手实验, 提供部分免费实验,但大部分实验所需的积分都需要购买。高性价比的做法是, 注册一个AWS全球账号,使用一年的免费额度来对照着实验手册来进行试验。
- 学习 AWS 白皮书
- 白皮书是纯英文的,而且每个白皮书篇幅都很长,读起来既费时又枯燥。但是有时间还是建议把推荐的几个都看一下。
- 查看 AWS 常见问题
- 参加模拟考试
- 20美刀一次,主要目的是为了让人熟悉考试时上机的流程。是否需要因人而异, 特别想先熟悉下考试流程的可以考虑参加一次。我个人觉得没有必要, 因为真实考试时,操作界面一目了然,没有磕磕绊绊的机关,省下20美刀可以去买一份课程。
- 报名考试并获得认证
考试指南
AWS Certified SysOps Administrator - Associate 考试指南 读三遍,读三遍,读三遍
各个Domain的分数比例如下: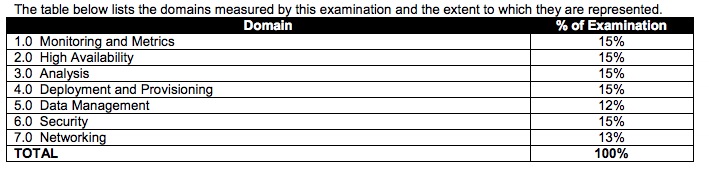
视频学习
Acloudguru 中aws-certified-sysops-administrator-associate视频的学习
要点摘录
Overview
- Introduction
- Monitoring, Metrics & Analysis
- High Availability
- Deployment & Provisioning
- Data Management
- OpsWorks
- Security
- Networking
- VPCs
Monitoring, Metrics & Analysis
CloudWatch
Amazon CloudWatch is a monitoring service to monitor your AWS resources, as well as the applications that you run on AWS.
CloudWatch can monitor things like :
- Compute
- Autoscaling Groups
- Elastic Load Balancers
- Route53 Health Checks
- Storage & Content Delivery
- EBS Volumes
- Storage Gateways
- CloudFront
- Database & Analytics
- DynamoDB
- Elasticache Nodes
- RDS Instances
- Elastic MapReduce Job Flows
- Redshift
- Other
- SNS Topics
- SQS Queues
- Opsworks
- CloudWatch Logs
- Estimated Charges on your AWS Bill
- Compute
CloudWatch and EC2
- Host Level Metrics Consist of:
- CPU
- Network
- Disk
- Status Check
- RAM Utilization is a custom metric! By default EC2 monitoring is 5 minute intervals, unless you enable detailed monitoring which will then make it 1 minute intervals.
- EC2 Metric
- CPUCreditUsage - Units: Count
- CPUCreditBalance - Units: Count
- CPUUtilization - Units: Percent
- DiskReadOps - Units: Count
- DiskWriteOps - Units: Count
- DiskReadBytes - Units: Bytes
- DiskWriteBytes - Units: Bytes
- NetworkIn - Units: Bytes
- NetworkOut - Units: Bytes
- NetworkPacketsIn - Units: Count
- NetworkPacketsOut - Units: Count
- StatusCheckFailed - Units: Count
- StatusCheckFailed_Instance - Units: Count
- StatusCheckFailed_System - Units: Count
- EC2 Dimension
If you’re using Detailed Monitoring, you can filter the EC2 instance data using any of the dimensions in the following table.- AutoScalingGroupName
- ImageId
- InstanceId
- InstanceType
- By Default - CloudWatch Metric stored 2 Weeks. You can retrieve data that is longer than 2 weeks using the GetMetricStatistics API or by using third party tools offered by AWS partners.
- You can retrieve data from any terminated EC2 or ELB instance for up to 2 weeks after it’s termination.
- Host Level Metrics Consist of:
Metric Granularity
- It depends on the AWS service. Many default metrics for many default services are 1 minute, but it can be 3 or 5 minutes depending on the service.
- Exam Tips: For custom metric the minimum granularity that you can have is 1 minute.
CloudWatch Alarms
- You can create an alarm to monitor any Amazon CloudWatch metric in your account. This can include EC2 CPU Utilization, Elastic Loa Balancer Latency of even the charges on your AWS bill. You can set the appropriate thresholds in which to trigger the alarms and also set what actions should be taken if an alarm state is reached. This will be covered in a subsequent lecture.
EC2 Status check
- System Status Check (Checks Host, underlying physical Host)
- Loss of network connectivity
- Loss of system power
- Software issues on the physical host
- Hardware issues on the physical host
- Best way to resolve issues is to stop and then start the VM again.
- Instance Status Check (Checks VM)
- Failed system status checks
- Misconfigured networking or startup configuration
- Exhausted memory
- Corrupted file system
- Incompatible kernel
- Best way to trouble shoot is by rebooting the instance or by making modifications in your operating system.
- System Status Check (Checks Host, underlying physical Host)
Custom Metrics
- AWS Namespaces
- Custom Namespaces (the custom metric is selected in this namespace)
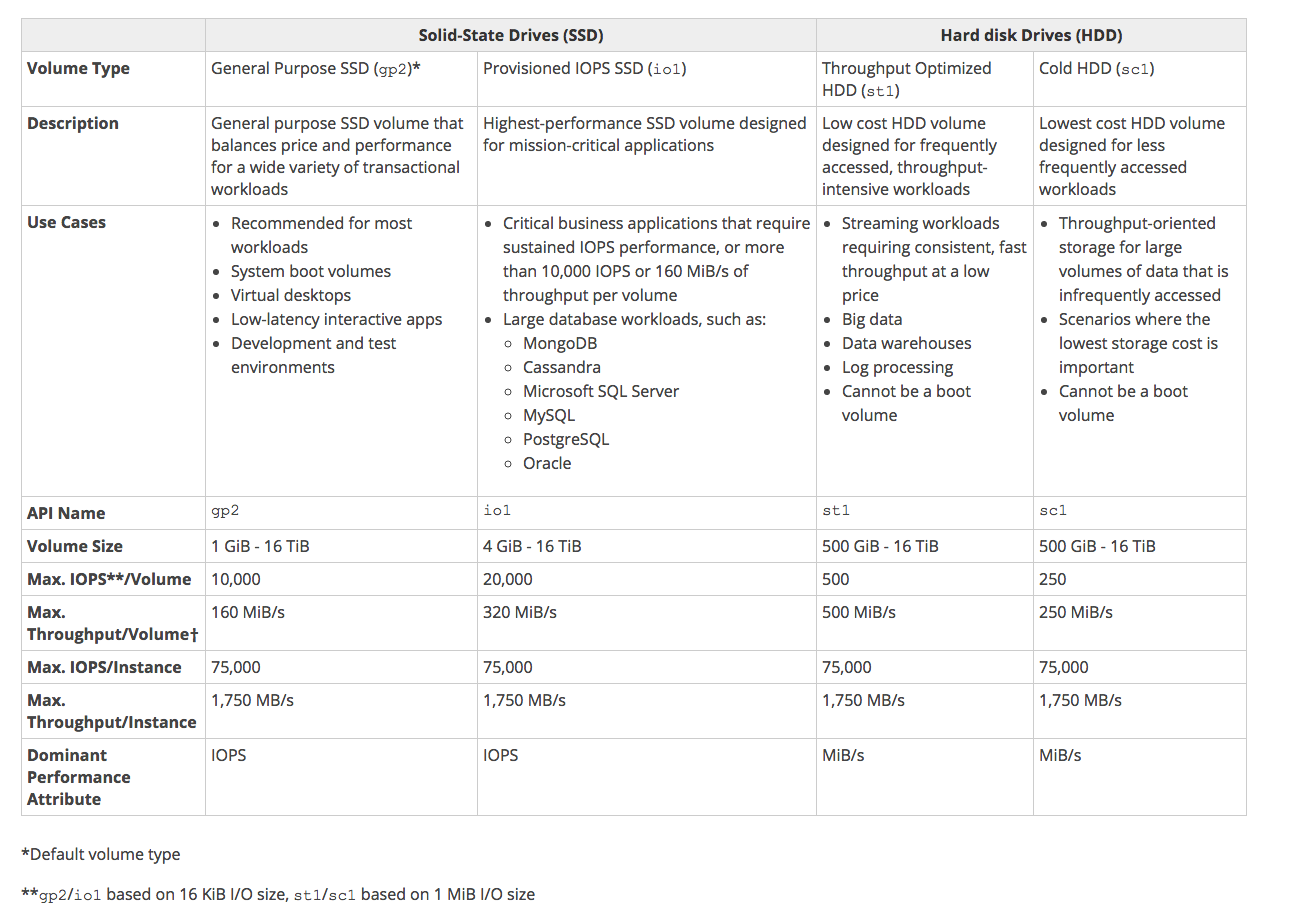
Monitoring EBS
4 Different Types of EBS Storage
- General Purpose (SSD) - gp2
- Provisioned IOPS(SSD) - io1
- Throughput Optimized(HDD) - st1
- Cold (HDD) - sc1
IOPS & Volumes
- General Purpose SSD volumes have a base of 3 IOPS per/GiB of volume size.
- Maximum volume size of 16,384 GiB
- Maximum IOPS Size of 10,000 IOPS Total (after that you need to move to provisioned IOPS)
- General Purpose SSD volumes have a base of 3 IOPS per/GiB of volume size.
IOPS & Volumes Examples
- Say we have a 1 GiB Volume. We get 3 IOPS per Gb so we have 3*1=3 IOPS
- We can burst performance on this volume up to 3000 IOPS if we want
- Using I/O Credits
- The burst would be 2997 IOPS( 3000 - 3)
I/O Credits
- When your volume requires more than the baseline performance I/O level, it simply uses I/O credits in the credit balance to burst to the required performance level, up to a maximum of 3,000 IOPS.
- Each volume receives an initial I/O credit balance of 5,400,000 I/O credits.
- This is enough to sustain the maximum burst performance of 3,000 IOPS for 30 minutes.
- When you are not going over your provisioned IO level(ie bursting) you will be earning credits.
- When your volume requires more than the baseline performance I/O level, it simply uses I/O credits in the credit balance to burst to the required performance level, up to a maximum of 3,000 IOPS.
I/O Credits - it is beyond the scope of the SysOps Associate Exam to be able to calculate this.
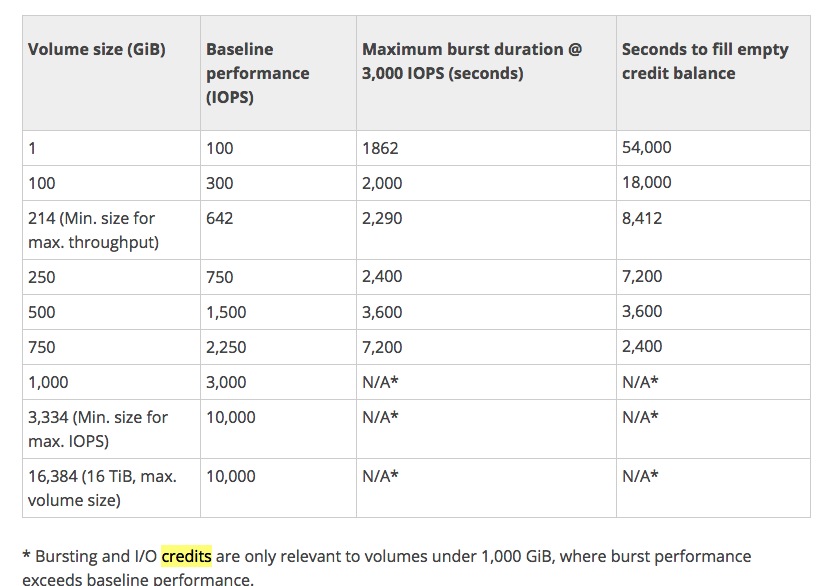
-
- New EBS volumes receive their maximum performance the moment that they are available and do not require initialization (formerly known as pre-warming). However, storage blocks on volumes that were restored from snapshots must be initialized (pulled down from Amazon S3 and written to the volume) before you can access the block. This preliminary action takes time and can cause a significant increase in the latency of an I/O operation the first time each block is accessed. For most applications, amortizing this cost over the lifetime of the volume is acceptable. Performance is restored after the data is accessed once.
- You can avoid this performance hit in a production environment by reading from all of the blocks on your volume before you use it; this process is called initialization. For a new volume created from a snapshot, you should read all the blocks that have data before using the volume.
-
- Exam Tips
- Degraded or Severely Degraded = Warning
- Stalled or Not Available = Impaired
- Exam Tips
-
- If your Amazon EBS volume is attached to a current generation EC2 instance type, you can increase its size, change its volume type, or (for an io1 volume) adjust its IOPS performance, all without detaching it. You can apply these changes to detached volumes as well.
- Issue the modification command (console or command line)
- Monitor the progress of the modification
- If the size of the volume was modified, extend the volume’s file system to take advantage of the increased storage capacity.
- If your Amazon EBS volume is attached to a current generation EC2 instance type, you can increase its size, change its volume type, or (for an io1 volume) adjust its IOPS performance, all without detaching it. You can apply these changes to detached volumes as well.
Monitoring RDS
- Two Type of monitoring available for RDS
- CloudWatch - In CloudWatch you can monitor RDS by Metrics.
- RDS itself - In RDS itself, you can monitor RDS by Events.
- RDS Metrics
- BinLogDiskUsage - Units: Bytes
- CPUUtilization - Units: Percent
- DatabaseConnections - Units: Count
- DiskQueueDepth - Units: Count
- FreeableMemory - Units: Bytes
- FreeStorageSpace - Units: Bytes
- ReplicaLag - Units: Seconds
- SwapUsage - Units: Bytes
- ReadIOPS - Units: Count/Second
- WriteIOPS - Units: Count/Second
- ReadLatency - Units: Seconds
- WriteLatency - Units: Seconds
- ReadThroughput - Units: Bytes/Second
- WriteThroughput - Units: Bytes/Second
- NetworkReceiveThroughput - Units: Bytes/second
- NetworkTransmitThroughput - Units: Bytes/second
- Have a general idea of what each metric does. You do not need to know the name of each metric, but pay attention to the ones in bold.
- Two Type of monitoring available for RDS
Monitoring ELB
- ELB - Every 60 seconds (Provided there is traffic)
Elastic Load Balancing only reports when requests are flowing through the load balancer. If there are no requests or data for a given metric, the metric will not be reported to CloudWatch. If there are requests flowing through the load balancer, Elastic Load Balancing will measure and send metrics for that load balancer in 60 second intervals - ELB Metrics
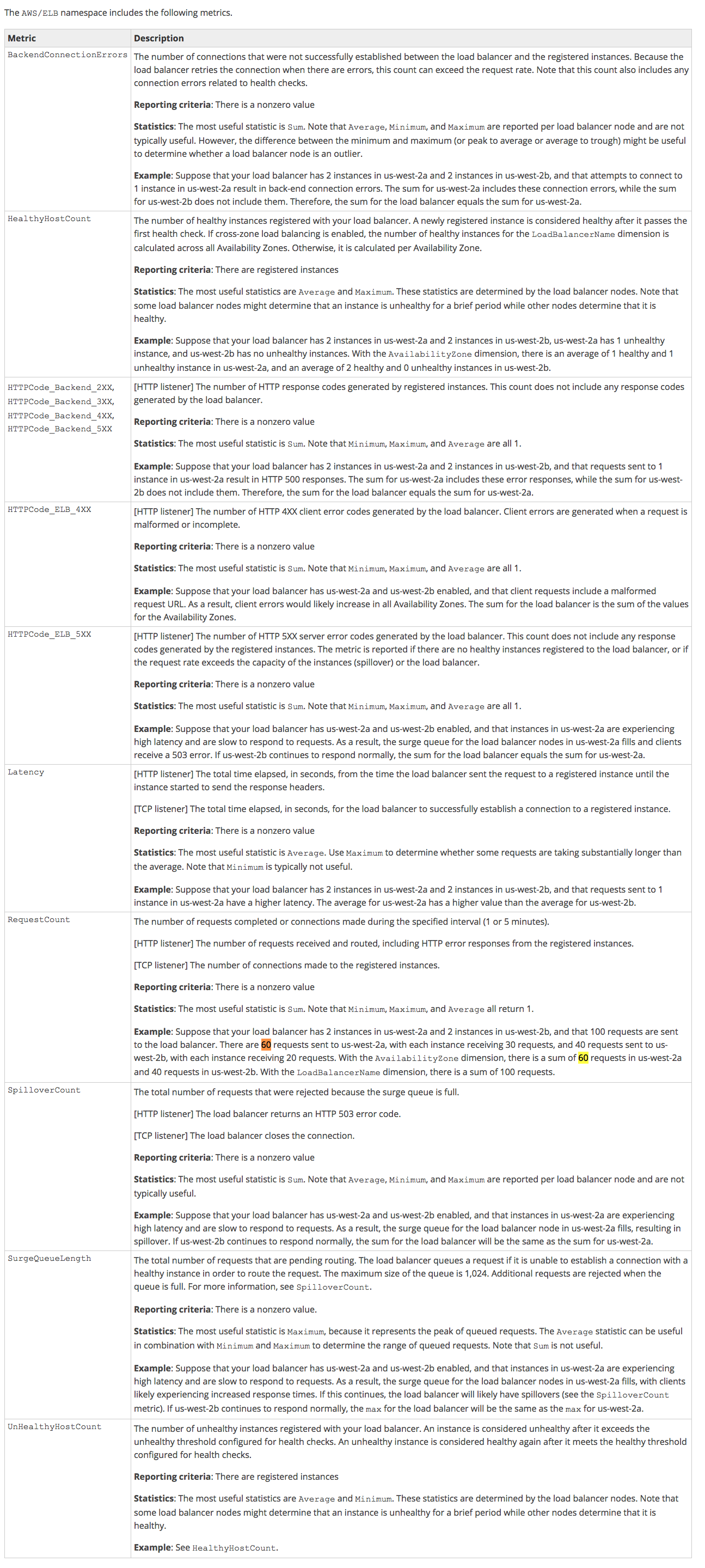
- Have a general idea of what each metric does. You do not need to know the name of each metric, but pay attention to SurgeQueueLength & SpilloverCount.
- ELB - Every 60 seconds (Provided there is traffic)
Monitoring Elasticache
- Two engines
- Memcached
- Redis
- Four important things
- CPU Utilization
- Swap Usage
- Evictions
- Concurrent Connections
- CPU Utilization
- Memcached
- Multi-threaded
- Can handle loads of up to 90%. If it exceeds 90% add more nodes to the cluster
- Redis
- Not multi-threaded. To determine the point in which to scale, take 90 and divide by the number of cores
- For example, suppose you are using a cache.m1.xlarge node, which has four cores. In this case, the threshold for CPU Utilization would be (90/4), or 22.5%
- You will not have to calculate Redis CPU Utilization in the exam.
- Memcached
- Swap Usage
- Put simply, swap usage is simply the amount of the Swap file that is used. The Swap File (or Paging File) is the amount of disk storage space reserved on disk if your computer runs out of ram. Typically the size of the swap file = the size of the RAM. So if you have 4Gb of RAM, you will have a 4 GB Swap File.
- Memcached
- Should be around 0 most of the time and should not exceed 50Mb.
- If this exceeds 50Mb you should increase the memcached_connections_overhead parameter.
- The memcached_connections_overhead defines the amount of memory to be reserved for memcached connections and other miscellaneous overhead.
- Learn More: https://docs.aws.amazon.com/AmazonElastiCache/latest/UserGuide/ParameterGroups.Memcached.html
- Redis
- No SwapUsage metric, instead use reserved-memory
- Evictions
- Think of evictions like tenants in an apartment building. There are a number of empty apartments that slowly fill up with tenants. Eventually the apartment block is full, however more tenants need to be added.
- An Eviction occurs when a new item is added and an old item must be removed due to lack of free space in the system.
- Memcached
- There is no recommended setting. Choose a threshold based off your application
- Either Scale up (ie increase the memory of existing nodes) OR
- Scale Out (add more nodes)
- Redis
- There is no recommended setting. Choose a threshold based off your application.
- scale your cluster up by using a larger node type.
- This can be an exam question. Remember the different approaches between Memcached & Redis
- Concurrent Connections
- Memcached & Redis
- There is no recommended setting. Choose a threshold based off your application
- If there is a large and sustained spike in the number of concurrent connections this can either mean a large traffic spike OR your application is not releasing connections as it should be
- This can be an exam question. Remember to set an alarm on the number of concurrent connections for elasticache.
- Memcached & Redis
- Two engines
Centralized Monitoring
Most enterprises have monitoring solutions such as Zennos, Nimsoft,Splunk, IBM Tivoli, HP Operations Manager etc. These usually involve installing agents on the servers to be monitored and then allowing these agents to report metrics back to the centralized monitoring server.- Protocol
- Depends on what is being monitored. Most basic monitoring is going to use ICMP
- Could be SQL (1433) or MySQL (3306)
- Exam Tip: This can come up in several areas of the exam. This could include either inside your own VPC or a VPC that is connected to your on premise data center. Remember to allow ICMP/Specific Ports to either a specific IP address or a specific range of IP Addresses.
- Protocol
AWS Organizations & Consolidated Billing
- AWS Organizations
AWS Organizations is an account management service that enables you to consolidate multiple AWS accounts into an organization that you create and centrally manage.- Available in two feature sets:
- Consolidated Billing
- ALL Features
- consist of
- Root
- Organization Unit (OU)
- AWS Account
- Available in two feature sets:
- Consolidated Billing
- Accounts
- Paying Account (Paying account is independent. Cannot access resources of the other accounts)
- Linked Accounts (All linked accounts are independent)
- Advantages
- One bill per AWS account
- Very easy to track charges and allocate costs
- Volume pricing discount
- S3 pricing
- Reserved EC2 Instances
- Best Practices
- Always enable multi-factor authentication on root account.
- Always use a strong and complex password on root account.
- Paying account should be used for billing purposes only. Do not deploy resources in to paying account.
- Notes
- Linked Accounts
- 20 linked accounts only
- To add more visit https://aws-portal.amazon.com/gp/aws/html-forms-controller/contactus/aws-account-and-billing
- Billing Alerts
- When monitoring is enabled on the paying account the billing data for all linked accounts is included
- You can still create billing alerts per individual account
- CloudTrail
- Per AWS Account and is enabled per region.
- Can consolidate logs using an S3 bucket.
- Turn on CloudTrail in the paying account
- Create a bucket policy that allows cross account access
- Turn on CloudTrail in the other accounts and use the bucket in the paying account
- Linked Accounts
- Exam Tips:
- Consolidated billing allows you to get volume discounts on all your accounts.
- Unused reserved instances for EC2 are applied across the group.
- CloudTrail is on a per account and per region basis but can be aggregate in to a single bucket in the paying account.
- Accounts
- AWS Organizations
EC2 Cost Optimization
- EC2 Instance Types
- On Demand
- Reserved
- Spot Price
- Spot Instances
Spot Instances allow you to name your own price for Amazon EC2 computing capacity. You simply bid on spare Amazon EC2 instances and these will run automatically whenever your bid exceeds the current Spot Price, which varies in real-time based on supply and demand. If your bid goes below the spot price after these instances are provisioned, your instances will automatically be terminated. - On Demand
- On-Demand Instances let you pay for compute capacity by the hour with no long-term commitments or upfront payments. You can increase or decrease your compute capacity depending on the demands of your application and only pay the specified hourly rate for the instances you use. Amazon EC2 always strives to have enough On-Demand capacity available to meet your needs, but during periods of very high demand, it is possible that you might not be able to launch specific On-Demand instance types in specific Availability Zones for short periods of time.
- Reserved
- Reserved Instances provide you with a significant discount (up to 75%) compared to On-Demand Instance pricing. You are assured that your Reserved Instance will always be available for the operating system (e.g. Linux/UNIX or Windows) and Availability Zone in which you purchased it. For applications that have steady state needs, Reserved Instances can provide significant savings compared to using On-Demand Instances. Functionally, Reserved Instances and On-Demand Instances perform identically.
- EC2 Instance Types

High Availability
Elasticity and Scalability
- What is Elasticity
- Think of elasticity as a rubber band. Elasticity allows you to stretch out and retract back your infrastructure, based on your demand.
- Under this model you only pay for what you need.
- Elasticity is used during a short time period, such as hours or days.
- What is Scalability
- Scalability is used to talk about building out the infrastructure to meet your demands long term.
- Scalability is used over longer time periods, such as weeks, days, months and years.
- AWS Services - Scalability vs Elasticity
- EC2
- Scalability - Increase Instance Sizes as required, using reserved instances
- Elasticity - Increase the number of EC2 instances, based on autoscaling
- DynamoDB
- Scalability - Unlimited amount of storage
- Elasticity - Increase additional IOPS for additional spikes in traffic. Decrease that IOPS after the spike.
- RDS
- Scalability - Increase instance size, eg from small to medium
- Elasticity - not very elastic, can’t scale RDS based on demand
- Automated Elasticity + Scalability
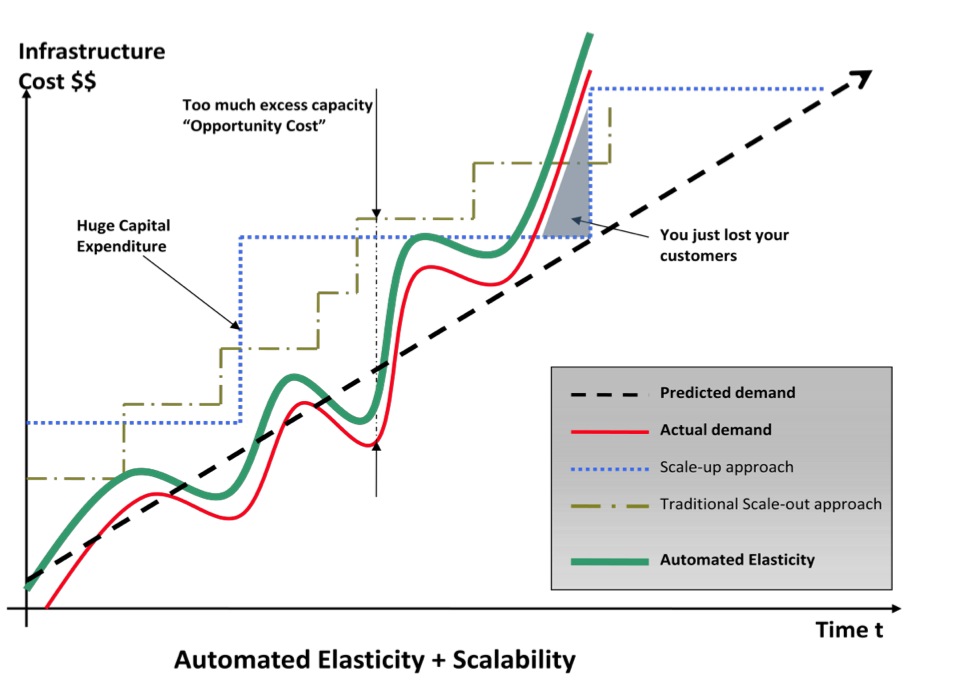
- EC2
- What is Elasticity
Scale Up or Scale Up
- Scaling Up - 向上升级
- Traditional IT - increases the number of processors, the number of RAM or the amount of storage.
- EC2 - increase th instance type from say T1.micro to T2.small, T2.medium etc
- Scaling Out - 横向扩展
- Traditionally - adding more resources (such as webservers)
- EC2 - adding additional EC2 Instances and using autoscaling.
- In the exam
- Eliminate the obviously incorrect answers
- ask yourself where the bottle neck is? Is it network related? If so it’s probably a scale up answer.
- Is the problem in relation to not having enough resources (ie you can’t increase the instance size further)? If so, it’s probably a scale out answer.
- Remember elasticity. Scaling out, you can scale back. Scaling up is easy, scaling down is not so easy.
- Scaling Up - 向上升级
RDS Multi-AZ Failover
- Introduction
- Multi-AZ deployments for the MySQL, Oracle and PostgreSQL engines utilize synchronous physical replication to keep data on the standby up-to-date with the primary.
- Mylti-AZ deployments for the SQLServer engine use synchronous logical replication to achieve the same result, employing SQL Server-native Mirroring technology.
- Both approaches safeguard your data in the event of a DB Instance failure or loss of an Availability Zone.
- RDS Multi-AZ Failover Advantages
- High availability
- Backups are taken from secondary which avoids I/O suspension to the primary
- Restore’s are taken from secondary which avoids I/O suspension to the primary
- Exam Tip: You can force a failover from one AZ to another by rebooting your instance. This can be done through the AWS Management console or by using RebootDbInstance API call.
- RDS Multi-AZ Failover is not a scaling solution
- Read Replica’s are used to scale
- Introduction
RDS Read Replicas
- What are Read Replica
- Read Replicas make it easy to take advantage of supported engine’s built-in replication functionality to elastically scale out beyond the capacity constraints of a single DB Instance for read-heave database workloads.
- Read only copies of your database.
- You can create a Read Replica with a few clicks in the AWS Management Console or using the CreateDBInstanceReadReplica API. Once the Read Replica is created, database updates on the source DB Instance will be replicated using a supported engine’s native, asynchronous replication. You can create multiple Read Replicas for a given source DB Instance and distribute your application’s read traffic amongst them.
- When would you use read replica’s
- Scaling beyond the compute or I/O capacity of a single DB Instance for read-heavy database workloads. This excess read traffic can be directed to one or more Read Replicas
- Serving read traffic while the source DB Instance is unavailable. If your source DB Instance cannot take I/O requests (e.g. due to I/O suspension for backups or scheduled maintenance), you can direct read traffic to your Read Replica
- Business reporting or data warehousing scenarios; you may want business reporting queries to run against a Read Replica, rather than your primary, production DB Instance.
- Supported Versions
- MySQL
- PostgreSQL
- MariaDB
- For all 3 Amazon uses these engines native asynchronous replication to update the read replica
- Aurora
- Aurora employees an SSD-backed virtualized storage layer purpose-built for database workloads. Amazon Aurora replica share the same underlying storage as the source instance, lowering costs and avoiding the need to copy data to the replica nodes.
- Creating Read Replicas
- When creating a new Read Replica, AWS will take a snapshot of your database.
- If Multi-AZ is not enabled:
- This snapshot will be of your primary database and can cause brief I/O suspension for around 1 minute.
- If Multi-AZ is enabled:
- The snapshot will be of your secondary database and you will not experience any performance hits on your primary database.
- Connecting to Read Replica
- When a new read replica is created you will be able to connect to it using a new end point DNS address.
- Read Replica’s Can Be Promoted
- You can promote a read replica to it’s own standalone database. Doing this will break the replication link between the primary and the secondary.
- Exam Tips - 1
- You can have up to 5 read replicas for MySQL, PostgreSQL & MariaDB
- You can have read replicas in different Regions for all engines
- Replication is Asynchronous
- Read Replica’s can be built off Multi-AZ’s databases
- But Read Replica’s themselves cannot be Multi-AZ currently
- You can have Read Replica’s of Read Replica’s beware of latency
- DB Snapshots and Automated backups cannot be taken of read replicas
- Key Metric to look for is Replica Lag
- Know the difference between read replicas and multi-AZ
- Exam Tips - 2
- If you can’t create a Read Replica, you most likely have disabled Database backups. Modify the database and turn them on.
- You can create read replicas of read replicas in multiple Regions
- You can either modify the database itself or create a new database from a snapshot
- Endpoints will NOT change if you modify a database, they will change if you create a new database from a snap or if you create a read replica
- You can manually fail over a Multi-AZ database from one AZ to another by rebooting it.
- What are Read Replica
Bastion Hosts & High Availability
- What is a Bastion Host
- A bastion host is a security measure that you can implement which acts as a gateway between you and your EC2 instances. The bastion host helps to reduce attack vectors on your infrastructure and means that you only have to harden 1 or 2 EC2 instances, rather than your entire fleet.
- What is a Bastion Host
Troubleshooting Autoscaling
- Instances not launching in to Autoscaling Groups
Below is a list of things to look for if your instances are not launching in to an autoscaling group:- Associate Key Pair does not exist
- Security group does not exist
- Autoscaling config is not working correctly
- Autoscaling group not found
- Instance type specified is not supported in the AZ
- AZ is no longer supported
- Invalid EBS device mapping
- Autoscaling service is not enabled on your account
- Attempting to attach and EBS block device to an instance-store AMI
- Instances not launching in to Autoscaling Groups
Deployment and Provisioning
Services with root/admin access to Operating System
- This is a very popular question in both the Solutions Architect Associate Exam & the SysOps Administrator Associate Exam
- Elastic Beanstalk
- Elastic MapReduce
- OpsWork
- EC2
- Exam Tips: There’s a good change this will be worth 1 point in your exam, so remember these services. Remember that you do not have access to RDS, DynamoDB, S3 or Glacier
- This is a very popular question in both the Solutions Architect Associate Exam & the SysOps Administrator Associate Exam
Elastic Load Balancer Configurations
- Exam Tips
- You can use Elastic Load Balancers to load balance across different availability zones within the same region, but not to different regions (or different VPC’s) themselves.
- An ELB and a NAT are different things entirely.
- Two types of ELB
- External Elastic Load Balancers (with external DNS names)
- Internal Elastic Load Balancers (with internal DNS names)
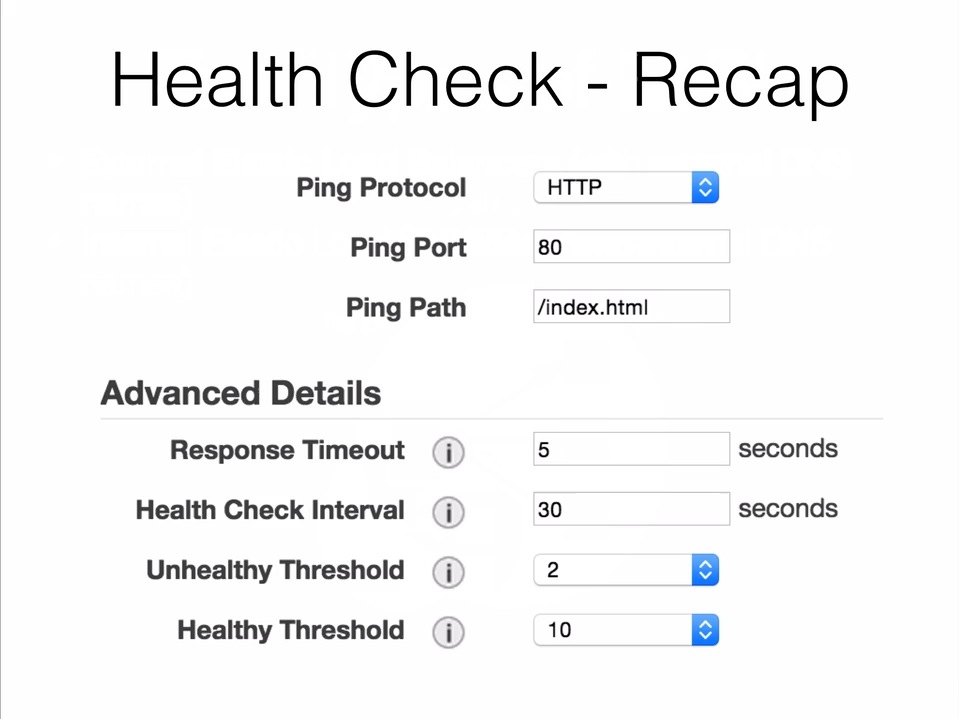
- Health Check - Recap
- Sticky Sessions
By default, a load balancer routes each request independently to the application instance with the smallest load.
However, you can use the sticky session feature (also known as session affinity), which enables the load balancer to lock a user down to a specific web server (EC2 instance).
This ensures that all requests from the user during the session are always sent to the same server.
The key to managing sticky sessions is to determine how long your load balancer should consistently route the user’s request to the same application instance.- Sticky Session Types
- Duration Based Session Stickiness
- Application-Controlled Session Stickiness
- Edit in the [Port Configuration] setting in the [Description] tab.
- Duration Based
Most commonly used. The load balancer itself creates the session cookie.
When the load balancer receives a request, it first checks to see if this cookie is present in the request. If so, the request is sent to the application instance specified in the cookie. If there is no cookie, the load balancer chooses an application instance based on the existing load balancing algorithm and adds a new cookie in to the response.
The stickiness policy configuration defines a cookie expiration, which established the duration of validity for each cookie. The cookie is automatically updated after its duration expires.
If an application instance fails or becomes unhealthy, the load balancer stops routing request to that instance, instead chooses a new instance based on the existing load balancing algorithm. The request is routed to the new instance as if there is no cookie and the session is no longer sticky. - Application Controlled
The load balancer uses a special cookie to associate the session with the instance that handled the initial request, but follows the lifetime of the application cookie specified in the policy configuration. The load balancer only inserts a new stickiness cookie if the application response includes a new application cookie. The load balancer stickiness cookie does not update with each request. If the application cookie is explicitly removed or expires, the session stops being sticky until a new application cookie is issued.
If an instance fails or becomes unhealthy, the load balancer stops routing requests to that instance, and chooses a new healthy instance based on the existing load balancing algorithm. The load balancer treats the session as now “stuck” to the new healthy instance, and continues routing requests to that instance even if the failed instance comes back. However, it is up to the new application instance whether and how to respond to a session which it has not previously seen.
- Sticky Session Types
- Exam Tips
Pre-warming the Elastic Load Balancer
- What is ‘Pre-warming’ for ELB
- AWS Staff can pre-configure the load balancer to have the appropriate level of capacity based on expected traffic.
- This is used in certain scenarios, such as when flash traffic is expected, or in the case where a load test cannot be configured to gradually increase traffic.
- This can be done by contacting AWS staff prior to the expected event. You will need to know the start and end dates of your expected flash traffic or test, the expected request rate per second and the total size of the typical request/response that you will be experiencing.
- What is ‘Pre-warming’ for ELB
Data Management
Disaster Recovery
- Back Up & Disaster Recovery is quite a key component of the SysOps Exam. It’s important to understand the key concepts well. You can also want to read the following white paper: https://media.amazonwebservices.com/AWS_Disaster_Recovery.pdf
- What is Disaster Recovery
- Disaster recovery (DR) is about preparing for and recovering from a disaster. Any event that has a negative impact on a company’s business continuity or finances could be termed a disaster. This includes hardware or software failure, a network outage, a power outage, physical damage to a building like fire or flooding, human error, or some other significant event.
- Traditional Approaches to DR
- A traditional approach to DR usually involves an N+1 approach and has different levels of off-site duplication of data and infrastructure.
- Facilities to house the infrastructure, including power and cooling
- Security to ensure the physical protection of assets
- Suitable capacity to scale the environment
- Support for repairing, replacing, and refreshing the infrastructure
- Contractual agreements with an Internet service provider (ISP) to provide Internet connectivity that can sustain bandwidth utilization for the environment under a full load
- Network infrastructure such as firewalls, routers, switches, and load balancers
- Enough server capacity to run all mission-critical services, including storage appliances for the supporting data, and servers to run applications and backend services such as user authentication, Domain Name System (DNS)
- Dynamic Host Configuration Protocol (DHCP), monitoring, and alerting
- A traditional approach to DR usually involves an N+1 approach and has different levels of off-site duplication of data and infrastructure.
- Why use aws for DR
- Only minimum hardware is required for ‘data replication’
- Allows you to be flexible depending on what your disaster is and how to recover from it
- Open cost model (pay as you use) rather than heavy investment upfront. Scaling is quick and easy
- Automate disaster recovery deployment
- What Services
- Regions
- Storage
- S3 - 99.999999999% durability and Cross Region Replication
- Glacier
- Elastic Block Store (EBS)
- Direct Connect
- AWS Storage Gateway
- Gateway-cached volumes - store primary data and cache most recently used data locally.
- Gateway-stored volumes - store entire dataset on site and asynchronously replicate data back to S3
- Gateway-virtual tape library - Store your virtual tapes in either S3 or Glacier
- Compute
- EC2
- EC2 VM Import Connector - Virtual appliance which allows you to import virtual machine images from your existing environment to Amazon EC2 instances.
- Networking
- Route53
- Elastic Load Balancing
- Amazon Virtual Private Cloud (VPC)
- Amazon Direct Connect
- Database
- RDS
- DynamoDB
- Redshift
- Orchestration
- CloudFormation
- ElasticBeanstalk
- OpsWork
- Lambda
- RTO vs RPO
- Recovery Time Objective (RTO)
- RTO is the length of time from which you can recover from a disaster. It is measured from when the disaster first occurred as to when you have fully recovered from it.
- Recovery Point Objective (RPO)
- RPO is the amount of data your organization is prepared to lose in the event of a disaster (1 days worth of emails, 5 hours of online transaction records etc, 24 hours of backup etc)
- Typically the lower RTO & RPO threshold, the more costly it solution will be.
- Recovery Time Objective (RTO)
- DR Scenarios
- Four Scenarios
- Backup & Restore
- Pilot Light
- Warm Standby
- Multi Site
- Backup & Restore
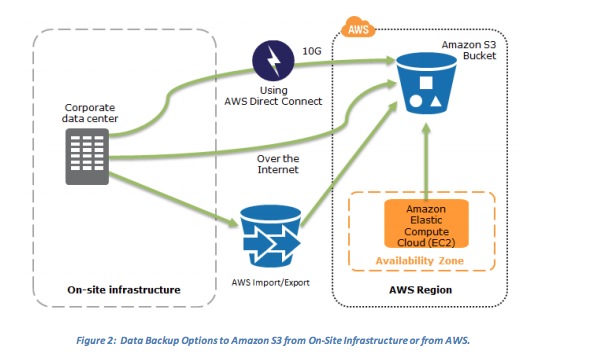
- In most traditional environments, data is backed up to tape and sent off-site regularly. If you use this method, it can take a long time to restore your system in the event of a disruption or disaster. Amazon S3 is an ideal destination for backup data that might be needed quickly to perform a restore. Transferring data to and from Amazon S3 is typically done through the network, and is therefore accessible from any location.
- You can use AWS Import/Export to transfer very large data sets by shipping storage devices directly to AWS. For longer-term data storage where retrieval times of several hours are adequate, there is Amazon Glacier, which has the same durability model as Amazon S3. . Amazon Glacier and Amazon S3 can be used in conjunction to produce a tiered backup solution.
- Data Backup Options to Amazon S3 from On-Site Infrastructure or from AWS.
- Restoring a System from Amazon S3 Backups to Amazon EC2
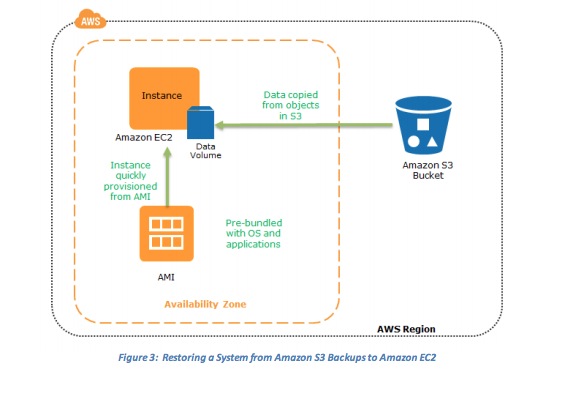
- Key steps for backup & restore
- Select an appropriate tool or method to back up your data into AWS.
- Ensure that you have an appropriate retention policy for this data.
- Ensure that appropriate security measures are in place for this data, including encryption and access policies.
- Regularly test the recovery of this data and the restoration of your system.
- Pilot Light
- The term pilot light is often used to describe a DR scenario in which a minimal version of an environment is always running in the cloud. The idea of the pilot light is an analogy that comes from the gas heater. In a gas heater, a small flame that’s always on can quickly ignite the entire furnace to heat up a house.
- This scenario is similar to a backup-and-restore scenario. For example, with AWS you can maintain a pilot light by configuring and running the most critical core elements of your system in AWS. When the time comes for recovery, you can rapidly provision a full-scale production environment around the critical core.
- Infrastructure elements for the pilot light itself typically include your database servers, which would replicate data to Amazon EC2 or Amazon RDS. Depending on the system, there might be other critical data outside of the database that needs to be replicated to AWS. This is the critical core of the system (the pilot light) around which all other infrastructure pieces in AWS (the rest of the furnace) can quickly be provisioned to restore the complete system.
- To provision the remainder of the infrastructure to restore business-critical services, you would typically have some preconfigured servers bundled as Amazon Machine Images (AMIs), which are ready to be started up at a moment’s notice. When starting recovery, instances from these AMIs come up quickly with their pre-defined role (for example, Web or App Server) within the deployment around the pilot light.
- From a networking point of view, you have two main options for provisioning:
- Use pre-allocated elastic IP address and associate them with your instances when invoking DR. You can also use pre-allocated elastic network interfaces (ENIs) with pre-allocated Mac Addresses for applications with special licensing requirements
- Use Elastic Load Balancing (ELB) to distribute traffic to multiple instances. You would then update your DNS records to point at your Amazon EC2 instance or point to your load balancer using a CNAME
- Preparation phase
- The Preparation Phase of the Pilot Light Scenario
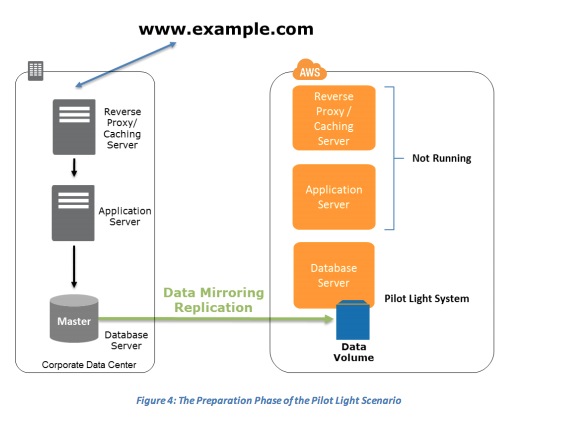
- Key steps for preparation:
- Set up Amazon EC2 instances to replicate or mirror data.
- Ensure that you have all supporting custom software packages available in AWS.
- Create and maintain AMIs of key servers where fast recovery is required.
- Regularly run these servers, test them, and apply any software updates and configuration changes.
- Consider automating the provisioning of AWS resources
- The Preparation Phase of the Pilot Light Scenario
- Recovery phase
- The Recovery Phase of the Pilot Light Scenario
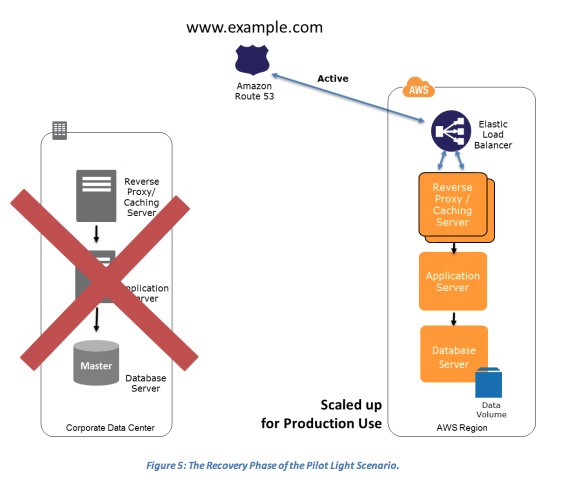
- Key steps for recovery:
- Start your application Amazon EC2 instances from your custom AMIs.
- Resize existing database/data store instances to process the increased traffic.
- Add additional database/data store instances to give the DR site resilience in the data tier; if you are using Amazon RDS, turn on Multi-AZ to improve resilience.
- Change DNS to point at the Amazon EC2 servers.
- Install and configure any non-AMI based systems, ideally in an automated way.
- The Recovery Phase of the Pilot Light Scenario
- Warm Standby
- The term warm standby is used to describe a DR scenario in which a scaled-down version of a fully functional environment is always running in the cloud. A warm standby solution extends the pilot light elements and preparation. It further decreases the recovery time because some services are always running. By identifying your business-critical systems, you can fully duplicate these systems on AWS and have them always on.
- These servers can be running on a minimum-sized fleet of Amazon EC2 instances on the smallest sizes possible. This solution is not scaled to take a full-production load, but it is fully functional. It can be used for non-production work, such as testing, quality assurance, and internal use.
- In a disaster, the system is scaled up quickly to handle the production load. In AWS, this can be done by adding more instances to the load balancer and by resizing the small capacity servers to run on larger Amazon EC2 instance types.
- Horizontal scaling is preferred over vertical scaling
- Preparation phase
- The Preparation Phase of the Warm Standby Scenario
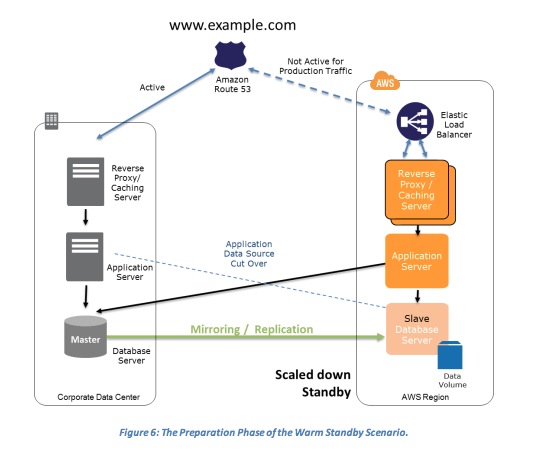
- Key steps for preparation:
- Set up Amazon EC2 instances to replicate or mirror data.
- Create and maintain AMIs.
- Run your application using a minimal footprint of Amazon EC2 instances or AWS infrastructure.
- Patch and update software and configuration files in line with your live environment.
- The Preparation Phase of the Warm Standby Scenario
- Recovery phase
- The Recovery Phase of the Warm Standby Scenario
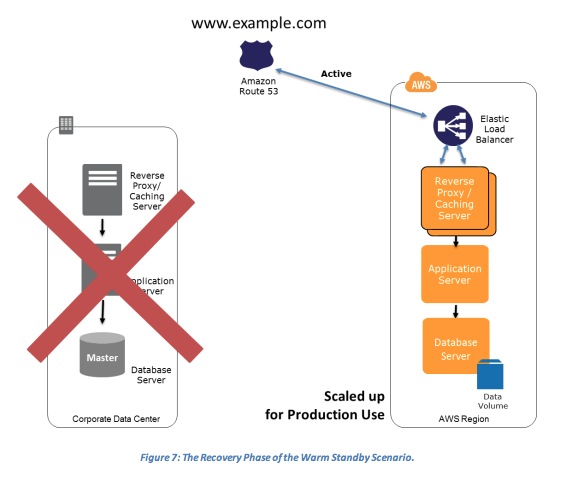
- Key steps for recovery:
- Increase the size of the Amazon EC2 fleets in service with the load balancer (horizontal scaling).
- Start applications on larger Amazon EC2 instance types as needed (vertical scaling).
- Either manually change the DNS records, or use Amazon Route 53 automated health checks so that all traffic is routed to the AWS environment.
- Consider using Auto Scaling to right-size the fleet or accommodate the increased load.
- Add resilience or scale up your database.
- The Recovery Phase of the Warm Standby Scenario
- Multi Site
- A multi-site solution runs in AWS as well as on your existing on-site infrastructure, in an active-active configuration. The data replication method that you employ will be determined by the recovery point that you choose.
- You can use Route53 to root traffic to both sites either symmetrically or asymmetrically.
- In an on-site disaster situation, you can adjust the DNS weighting and send all traffic to the AWS servers. The capacity of the AWS service can be rapidly increased to handle the full production load. You can use Amazon EC2 Auto Scaling to automate this process. You might need some application logic to detect the failure of the primary database services and cut over to the parallel database services running in AWS.
- Preparation phase
- The Preparation Phase of the Multi-Site Scenario
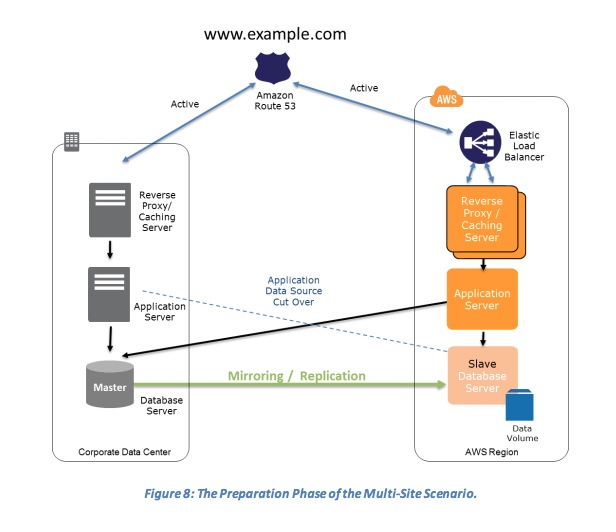
- Key steps for preparation:
- Set up your AWS environment to duplicate your production environment.
- Set up DNS weighting, or similar traffic routing technology, to distribute incoming requests to both sites. Configure automated failover to re-route traffic away from the affected site.
- The Preparation Phase of the Multi-Site Scenario
- Recovery phase
- The Recovery Phase of the Multi-Site Scenario Involving On-Site and AWS Infrastructure.
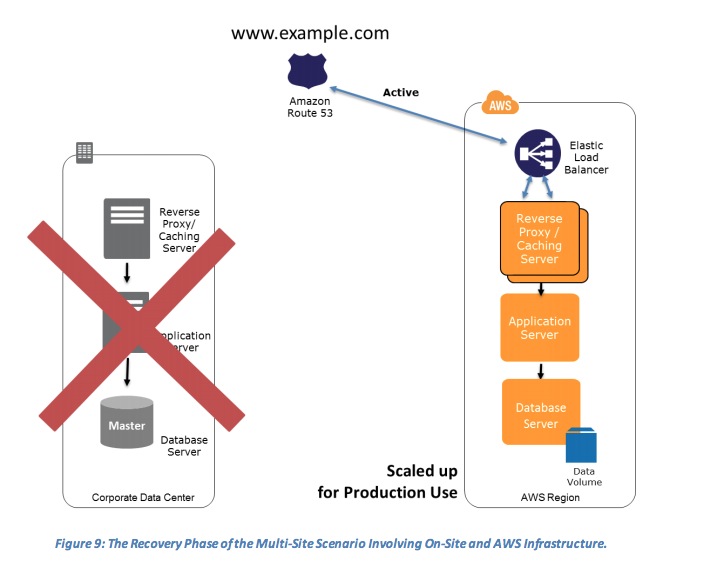
- Key steps for recovery:
- Either manually or by using DNS failover, change the DNS weighting so that all requests are sent to the AWS site.
- Have application logic for failover to use the local AWS database servers for all queries.
- Consider using Auto Scaling to automatically right-size the AWS fleet.
- The Recovery Phase of the Multi-Site Scenario Involving On-Site and AWS Infrastructure.
- Failing Back
- Backup and restore
- Freeze data changes to the DR site
- Take a backup
- Restore the backup to the primary site
- Re-point users to the primary site
- Unfreeze the changes
- Pilot light, warm standby, and multi-site:
- Establish reverse mirroring/replication from the DR site back to the primary site, once the primary site has caught up with the changes.
- Freeze data changes to the DR site
- Re-point users to the primary site
- Unfreeze the changes
- Backup and restore
- Exam Tips
Pay particular attention to the Pilot Light Scenario and specifically the fact that you can have Elastic Network Interfaces (ENI’s) with preconfigured MAC addresses.
- Four Scenarios
AWS Services and Automated Backups
- Services that have Automated Backup
- RDS
- Elasticache (Redis only)
- Redshift
- Services that do not have Automated Backup
- EC2
- RDS Automatd Backups
- For MySQL you need innoDB (transactional engine)
- There is a performance hit if Multi-AZ is not enabled
- If you delete an instance, then ALL automated backups are deleted
- However, manual DB snapshots will NOT be deleted
- All stored on S3
- When you do a restore, you can change the engine type (SQL Standard to SQL Enterprise for example). Provided you have enough storage space
- Elasticache Backups
- Available for Redis Cache Cluster only
- The entire cluster is snapshotted
- Snapshot will degrade performance
- Therefore only set your snapshot window during the least busy part of the day
- Stored on S3
- Redshift Backups
- Stored on S3
- By default, Amazon Redshift enables automated backups of your data warehouse cluster with a 1-day retention period
- Amazon Redshift only backs up data that has changed so most snapshots only use up a small amount of your free backup storage
- EC2
- No automated backups
- Backups degrade you performance, schedule these times wisely
- Snapshots are stored in S3
- Can create automated backups using either the command line interface or Python
- They are incremental:
- Snapshots only store incremental changes since last snapshot
- Only charged for incremental storage
- Each snapshot still contains the base snapshot data
- Services that have Automated Backup
EC2 Type - EBS vs Instance Store
- History
- When EC2 was first launched, all AMI’s were backed by Amazon’s Instance Store. Instance store is known as ephemeral storage, which simply means non-persistence or temporary storage.
- Later on AWS launched EBS, Elastic Block Storage, which allows users to have data persistence and to save their data permanently.
- Confusion
- There is a lot of confusion between instance store volumes and EBS volumes in the AWS community and you need to have a good understanding of the differences between the two. Let’s start with volumes. There are two types of volumes:
- Root Volume (this is where your operating system is installed)
- Additional Volumes (this can be your D:\ E:\ F:\ or /dev/sdb, /dev/sdc, /dev/sdd etc)
- There is a lot of confusion between instance store volumes and EBS volumes in the AWS community and you need to have a good understanding of the differences between the two. Let’s start with volumes. There are two types of volumes:
- Route Volume Sizes
- Root device volumes can either be EBS volumes or Instance Store volumes
- An Instance store root device volume’s maximum size is 10Gb
- EBS root device volume can be up to 1 or 2Tb depending on the OS
- Terminating an Instance - EBS
- EC2 Instances can be terminated:
- EBS root device volumes are terminated by DEFAULT when the EC2 instance is terminated. You can stop this b unselecting the “Delete on Termination” option when creating the instance or by setting the deleteontermination flag to false using the command line
- Other EBS volumes attached to the instance are preserved however, if you delete the instance
- Instance store device root volumes are terminated by DEFAULT when the EC2 instance is terminated. You cannot stop this
- Other instance store volumes will be deleted on termination automatically
- Other EBS volumes attached to the EC2 instance will persist automatically
- EC2 Instances can be terminated:
- Stopping an Instance
- EBS backed instances can be stopped
- Instance Store backed instances CANNOT be stopped. Only rebooted or terminated
- Instance Store Data
- The data in an instance store persists only during the lifetime of its associated instance. If an instance reboots (intentionally or unintentionally), data in the instance store persists. However, data on instance store volumes is lost under the following circumstances:
- Failure of an underlying drive
- Stopping an Amazon EBS-backed instance
- Terminating an instance
- The data in an instance store persists only during the lifetime of its associated instance. If an instance reboots (intentionally or unintentionally), data in the instance store persists. However, data on instance store volumes is lost under the following circumstances:
- Instance Store
- Therefore, do not rely on instance store volumes for valuable, long-term data. Instead, keep your data safe by using a replication strategy across multiple instances, storing data in Amazon S3, or using Amazon EBS volumes.
- Comparison EBS vs Instance Store

- Exam Tips
- ‘Delete on Termination’ is the default for all EBS root device volumes. You can set this to false however but only at instance creation time
- Additional volumes will persist automatically. You need to delete these manually when you delete an instance
- Instance Store is known as ephemeral storage, meaning that data will not persist after an instance is deleted. You cannot set this to false, data will always be deleted when that instance disappears
- History
Upgrading EBS volume types - Exam tips
- EBS volumes can be changed on the fly (except for magnetic standard).
- Best practice to stop the EC2 instance and then change the volume
- You can change volume types by taking a snapshot and then using the snapshot to create a new volume
- If you change a volume on the fly you must wait for 6 hours before making another change
- You can scale EBS Volumes up only
- Volumes must be in the same AZ as the EC2 instances.
Storing Log Files & Backups
- Centralized Monitoring & Logging
- You can monitor your environment in a number of ways:
- Using a third party, centralized monitoring platform, such as Zennos, Splunk, RSyslog, Kiwi etc. These logs can then be stored on S3.
- Using CloudWatch Logs (relatively new service)
- Utilizing Access Logging on S3 (S3 only)
- You can monitor your environment in a number of ways:
- Suggested to use S3
- The best place to store your logs is probably S3:
- 99.999999999% durability
- Life cycle management
- Archive off to Glacier
- Effectively allows you to Tier your back up solution
- The best place to store your logs is probably S3:
- Centralized Monitoring & Logging
OpsWorks
What is OpsWorks
- Cloud-based applications usually require a group of related resources—application servers, database servers, and so on—that must be created and managed collectively. This collection of instances is called a stack. A simple application stack might look something like the following.
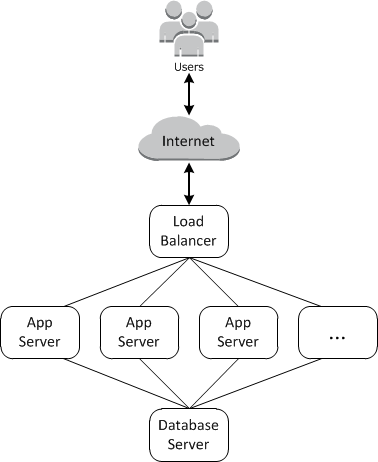
- AWS OpsWorks Stacks provides a simple and straightforward way to create and manage stacks and their associated applications and resources
- Amazon Definition:
- AWS OpsWorks is an application management service that helps you automate operational tasks like code deployment, software configurations, package installations, database setups, and server scaling using Chef. OpsWorks gives you the flexibility to define your application architecture and resource configuration and handles the provisioning and management of your AWS resources for you. OpsWorks includes automation to scale your application based on time or load, monitoring to help you troubleshoot and take automated action based on the state of your resources, and permissions and policy management to make management of multi-user environments easier.
- Cloud-based applications usually require a group of related resources—application servers, database servers, and so on—that must be created and managed collectively. This collection of instances is called a stack. A simple application stack might look something like the following.
What is Chef
- Chef turns infrastructure into code. With Chef, you can automate how you build, deploy, and manage your infrastructure. Your infrastructure becomes as versionable, testable, and repeatable as application code.
- Chef server stores your recipes as well as other configuration data. The Chef client is installed on each server, virtual machine, container, or networking device you manage - we’ll call these nodes. The client periodically polls Chef server latest policy and state of your network. If anything on the node is out of date, the client brings it up to date.
What is OpsWorks
- A GUI to deploy and configure your infrastructure quickly. OpsWorks consists of two elements, Stacks and Layers.
- A stack is a container (or group) of resources such as ELBS, EC2 instances, RDS instances etc.
- A layer exists within a stack and consists of things like a web application layer. An application processing layer or a Database layer.
- When you create a layer, rather than going and configuring everything manually (like installing Apache, PHP etc) OpsWorks takes care of this for you.
Layers
- 1 or more layers in the stack
- An instance must be assigned to at least 1 layer
- Which chef layers run, are determined by the layer the instance belongs to
- Preconfigured Layers include:
- Applications
- Databases
- Load Balancers
- Caching
Security
Security Token Service (STS)
- what is Security Token Service (STS)
- Grants users limited and temporary access to AWS resources. Users can come from three sources:
- Federation (typically Active Directory)
- Uses Security Assertion Markup Language (SAML)
- Grants temporary access based off the users Active Directory credentials. Does not need to be a user in IAM
- Single sign on allows users to log in to AWS console without assigning IAM credentials
- Federation with Mobile Apps
- Use Facebook/Amazon/Google or other OpenID providers to log in.
- Cross Account Access
- Let’s users from one AWS account access resources in another
- Federation (typically Active Directory)
- Grants users limited and temporary access to AWS resources. Users can come from three sources:
- Understanding Key Terms
- Federation: combining or joining a list of users in one domain (such as IAM) with a list of users in another domain (such as Active Directory, Facebook etc)
- Identity Broker: a service that allows you to take an identity from point A and join it (federate it) to point B
- Identity Store - Services like Active Directory, Facebook, Google etc
- Identities - a user of a service like Facebook etc.
- Scenario
- AWS blog [AWS Identity and Access Management – Now With Identity Federation]
- You are hosting a company website on some EC2 web servers in your VPC. Users of the website must log in to the site which then authenticates against the companies active directory servers which are based on site at the companies head quarters. Your VPC is connected to your company HQ via a secure IPSEC VPN. Once logged in the user can only have access to their own S3 bucket. How do you set this up?
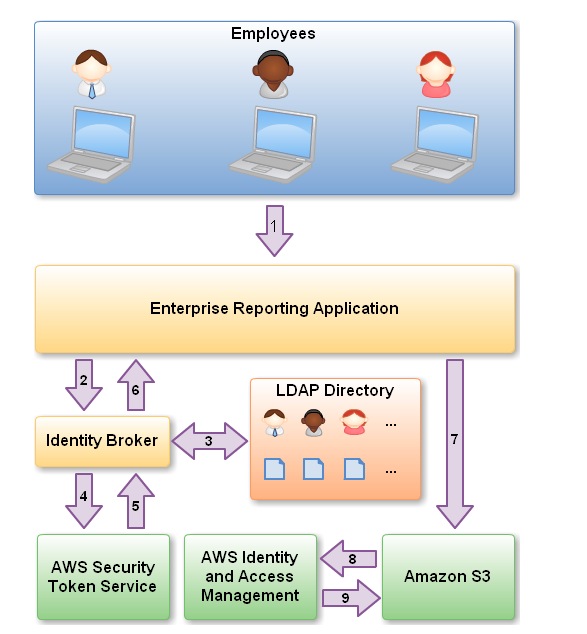
- Steps of scenario
- Employee enters their username and password
- The application calls an Identity Broker. The broker captures the username and password.
- The Identity Broker uses the organization’s LDAP directory to validate the employee’s identity.
- The Identity Broker calls the new GetFederationToken function using IAM credentials. The call must include an IAM policy and a duration (1 to 36 hours), along with a policy that specifies the permissions to be granted to the temporary security credentials.
- The Security Token Service confirms that the policy of the IAM user making the call to GetFederationToken gives permission to create new tokens and then returns four values to the application: An access key, a secret access key, a token, and a duration (the token’s lifetime).
- The Identity Broker returns the temporary security credentials to the reporting application.
- The data storage application uses the temporary security credentials (including the token) to make requests to Amazon S3.
- Amazon S3 uses IAM to verify that the credentials allow the requested operation on the given S3 bucket and key
- IAM provides S3 with the go-ahead to perform the requested operation.
- In the Exam
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, Then with AWS STS
- Application then gets temporary access to AWS resources
- Scenario 2
- steps of scenario
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, gets an IAM Role associate with a user
- Application then authenticates with STS and assumes that IAM Role
- Application uses that IAM role to interact with S3
- In the Exam
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, Then with AWS STS
- Application then gets temporary access to AWS resources
- steps of scenario
- what is Security Token Service (STS)
Overview of Security Processes
Shared Security Model
- AWS is responsible for securing the underlying infrastructure that supports the cloud. You’re responsible for anything you put on the cloud or connect to the cloud.
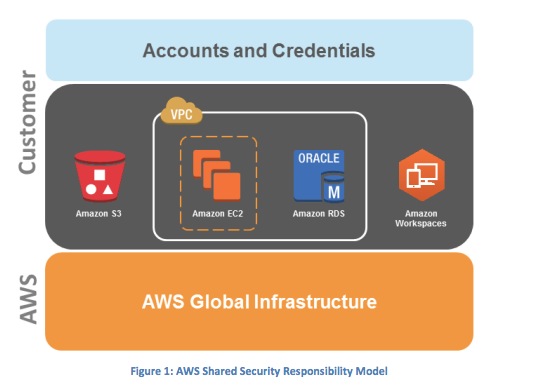
- AWS is responsible for securing the underlying infrastructure that supports the cloud. You’re responsible for anything you put on the cloud or connect to the cloud.
AWS Security Responsibilities
- Amazon Web Services is responsible for protecting the global infrastructure that runs all of the services offered in the AWS cloud. This infrastructure is comprised of the hardware, software, networking, and facilities that run AWS services.
- AWS is responsible for the security configuration of its products that are considered managed services. Examples of these types of services include Amazon DynamoDB, Amazon RDS, Amazon Redshift, Amazon Elastic MapReduce, Amazon WorkSpaces
Customer Security Responsibilities
- IAAS - —such as Amazon EC2, Amazon VPC, and Amazon S3—are completely under your control and require you to perform all of the necessary security configuration and management tasks.
- Managed Services at AWS is responsible for patching, antivirus etc, however you are responsible for account management and user access. Its recommended that MFA be implemented, communicate to these services using SSL/TLS and that API/user activity logging be setup with CloudTrail.
Storage Decommissioning
- When a storage device has reached the end of its useful life, AWS procedures include a decommissioning process that is designed to prevent customer data from being exposed to unauthorized individuals. AWS uses the techniques detailed in DoD 5220.22-M (“National Industrial Security Program Operating Manual “) or NIST 800-88 (“Guidelines for Media Sanitization”) to destroy data as part of the decommissioning process. All decommissioned magnetic storage devices are degaussed and physically destroyed in accordance with industry-standard practices.
Network Security
- Transmission Protection
- You can connect to an AWS access point via HTTP or HTTPS using Secure Sockets Layer (SSL), a cryptographic protocol that is designed to protect against eavesdropping, tampering, and message forgery
- For customers who require additional layers of network security, AWS offers the Amazon Virtual Private Cloud (VPC), which provides a private subnet within the AWS cloud, and the ability to use an IPsec Virtual Private Network (VPN) device to provide an encrypted tunnel between the Amazon VPC and your data center.
- Amazon Corporate Segregation
- Logically, the AWS Production network is segregated from the Amazon Corporate network by means of a complex set of network security / segregation devices.
- Transmission Protection
Network Monitoring & Protection
- Types
- DDos
- Man in the middle attacks (MITM)
- Ip Spoofing
- Port Scanning
- Packet Sniffing by other tenants
- Ip Spoofing
- The AWS-controlled, host-based firewall infrastructure will not permit an instance to send traffic with a source IP or MAC address other than its own.
- Port Scanning
- Unauthorized port scans by Amazon EC2 customers are a violation of the AWS Acceptable Use Policy. . You may request permission to conduct vulnerability scans as required to meet your specific compliance requirements. These scans must be limited to your own instances and must not violate the AWS Acceptable Use Policy. You must request a vulnerability scan in advance.
- Types
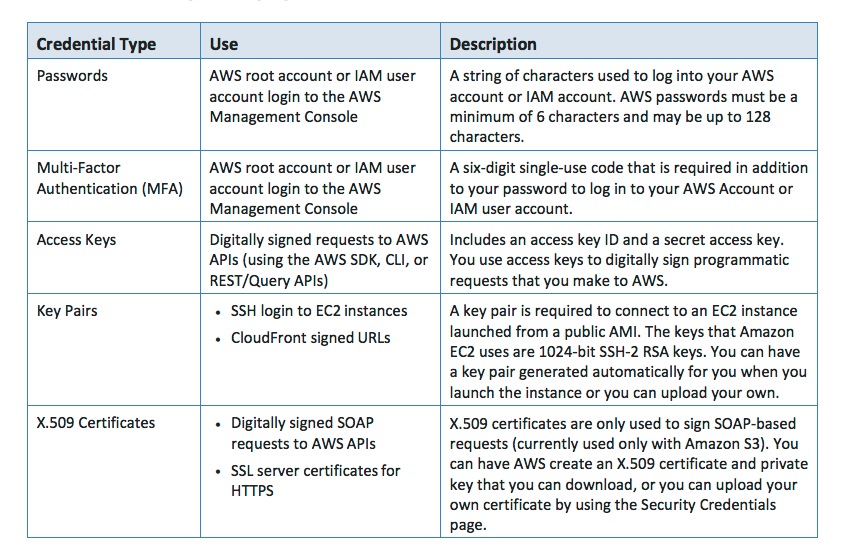
AWS Credentials
AWS Trusted Advisor
- Trusted Advisor inspects your AWS environment and makes recommendations when opportunities may exist to save money, improve system performance, or close security gaps. It provides alerts on several of the most common security misconfigurations that can occur, including leaving certain ports open that make you vulnerable to hacking and unauthorized access, neglecting to create IAM accounts for your internal users, allowing public access to Amazon S3 buckets, not turning on user activity logging (AWS CloudTrail), or not using MFA on your root AWS Account.
Instance Isolation
- Different instances running on the same physical machine are isolated from each other via the Xen hypervisor. Amazon is active in the Xen community, which provides awareness of the latest developments. In addition, the AWS firewall resides within the hypervisor layer, between the physical network interface and the instance’s virtual interface. All packets must pass through this layer, thus an instance’s neighbors have no more access to that instance than any other host on the Internet and can be treated as if they are on separate physical hosts. The physical RAM is separated using similar mechanisms.
- Customer instances have no access to raw disk devices, but instead are presented with virtualized disks. The AWS proprietary disk virtualization layer automatically resets every block of storage used by the customer, so that one customer’s data is never unintentionally exposed to another. In addition, memory allocated to guests is scrubbed (set to zero) by the hypervisor when it is unallocated to a guest. The memory is not returned to the pool of free memory available for new allocations until the memory scrubbing is complete.
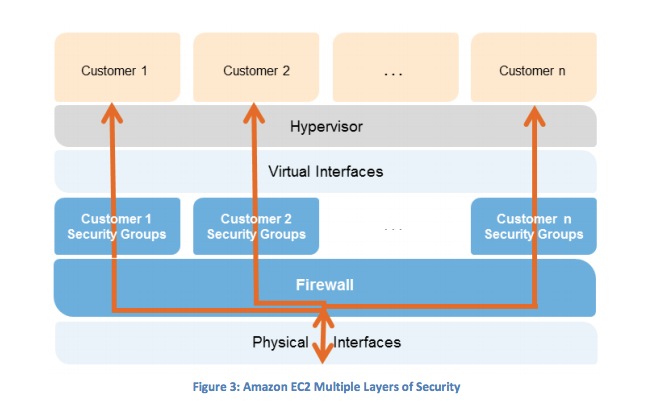
Other Considerations
- Guest Operating System - Virtual instances are completely controlled by you, the customer. You have full root access or administrative control over accounts, services, and applications. AWS does not have any access rights to your instances or the guest OS.
- Firewall - Amazon EC2 provides a complete firewall solution; this mandatory inbound firewall is configured in a default deny-all mode and Amazon EC2 customers must explicitly open the ports needed to allow inbound traffic.
- Elastic Block Storage(EBS) Security - Encryption of sensitive data is generally a good security practice, and AWS provides the ability to encrypt EBS volumes and their snapshots with AES-256. The encryption occurs on the servers that host the EC2 instances, providing encryption of data as it moves between EC2 instances and EBS storage. In order to be able to do this efficiently and with low latency, the EBS encryption feature is only available on EC2’s more powerful instance types (e.g., M3, C3, R3, G2).
- Elastic Load Balancing - SSL Termination on the load balancer is supported.
- Direct Connect
- Bypass Internet service providers in your network path. You can procure rack space within the facility housing the AWS Direct Connect location and deploy your equipment nearby. Once deployed, you can connect this equipment to AWS Direct Connect using a cross-connect.
- Using industry standard 802.1q VLANs, the dedicated connection can be partitioned into multiple virtual interfaces. This allows you to use the same connection to access public resources such as objects stored in Amazon S3 using public IP address space, and private resources such as Amazon EC2 instances running within an Amazon VPC using private IP space, while maintaining network separation between the public and private environments.
AWS & IT Audits
- Compliance
- SOC 1/SSAE 16/ISAE 3402 (formerly SAS 70 Type II)
- SOC2
- SOC3
- FISMA, DIACAP, and FedRAMP
- PCI DSS Level 1
- ISO 27001
- ISO 9001
- ITAR
- FIPS 140-2
- Several industry-specific standards:
- HIPAA
- Cloud Security Alliance (CSA)
- Motion Picture Association of America (MPAA)
- Auditing on AWS
- your organization may undergo an audit. This cloud be for PCI Compliance, ISO 27001, SOC etc. There is a level of shared responsibility in regards to audits:
- AWS Provides - their annual certifications and reports (ISO 27001, PCI-DSS certificates etc). Amazon are responsible the global infrastructure including all hardware, data centers, physical security etc
- Customer provides - everything they have put on AWS, such as EC2 instances, RDS instances, Applications, Assets in S3 etc. Essentially the organizations AWS assets (this can include the data itself)
- your organization may undergo an audit. This cloud be for PCI Compliance, ISO 27001, SOC etc. There is a level of shared responsibility in regards to audits:
- Compliance
Networking
- Route53
- ELB’s do not have pre-defined IPv4 addresses, you resolve to them using a DNS name.
- Understand the difference between an Alias Record and a CNAME
- Given the choice, always choose an Alias Record over a CNAME.
- Remember the different routing policies and their use cases.
- Simple
- Weighted
- Latency
- Failover
- Geolocation
VPC’s
Basic Info
- Think of a VPC as a logical datacenter in AWS
- Consists of IGW’s (Or Virtual Private Gateways), Route Tables, Network Access Control Lists, Subnets, Security Groups
- 1 Subnet = 1 Availability Zone
- Security Groups are Stateful, Network Access Control Lists are Stateless.
- Can Peer VPCs both in the same account and with other AWS accounts.
- No Transitive Peering
- Custom VPC network block size has to be between a /16 netmask and /28 netmask.
What can you do with a VPC
- Launch instances into a subnet of your choosing
- Assign custom IP address ranges in each subnet
- Configure route tables between subnets
- Create internet gateway and attach it to our VPC
- Much better security control over your AWS resources
- Instance security groups
- Subnet network access control lists (ACLS)
Default VPC vs Custom VPC
- Default VPC is user friendly, allowing you to immediately deploy instances
- All Subnets in default VPC have a route out to the internet.
- Each EC2 instance has both a public and private IP address
- If you delete the default VPC the only way to get it back is to contact AWS.
VPC peering
- Allows you to connect one VPC with another via a direct network route using private IP addresses.
- Instances behave as if they were on the same private network
- You can peer VPC’s with other AWS accounts as well as with other VPCs in the same account.
- Peering is in a star configuration, ie 1 central VPC peers with 4 others, NO TRANSITIVE PEERING!!!
Create VPC
- things automatically created
- Route tables
- Network ACLs
- Security Groups
- DHCP options set
- things are not automatically created
- Internet Gateways
- Subnets
- things automatically created
VPC Subnet
- There are 5 IP address reserved in each subnet by AWS, take CIDR block 10.0.0.0/24 as example
- 10.0.0.0 Network address
- 10.0.0.1 Reserved by AWS for the VPC router
- 10.0.0.2 Reserved by AWS for DNS
- 10.0.0.3 Reserved by AWS for future use.
- 10.0.0.255 Network broadcast address, we do not support broadcast in a VPC, therefore we reserve this address.
- There are 5 IP address reserved in each subnet by AWS, take CIDR block 10.0.0.0/24 as example
NAT instances
- When creating a NAT instance, Disable Source/Destination Check on the Instance
- NAT instance must be in a public subnet
- Must have an elastic IP address to work
- There must be a route out of the private subnet to the NAT instance, in order for this to work
- The amount of traffic that NAT instances supports, depends on the instance size. If you are bottlenecking, increase the instance size
- You can create high availability using Autoscaling Groups, multiple subnets in different AZ’s and a script to automate failover
- Behind a Security Group.
NAT Gateways
- Very new
- Preferred by the enterprise
- Scale automatically up to 10Gbps
- No need to patch
- Not associated with security groups
- Automatically assigned a public ip address
- Remember to update your route tables.
- No need to disable Source/Destination Checks.
NAT instances vs NAT Gateways
| Attribute | NAT gateway | NAT instance |
|---|---|---|
| Availability | Highly available. NAT gateways in each Availability Zone are implemented with redundancy. Create a NAT gateway in each Availability Zone to ensure zone-independent architecture. | Use a script to manage failover between instances. |
| Bandwidth | Supports bursts of up to 10Gbps. | Depends on the bandwidth of the instance type. |
| Maintenance | Managed by AWS.You do not need to perform any maintenance. | Managed by you, for example, by installing software updates or operating system patches on the instance. |
| Performance | Software is optimized for handling NAT traffic. | A generic Amazon Linux AMI that’s configured to perform NAT. |
| Cost | Charged depending on the number of NAT gateways you use, duration of usage, and amount of data that you send through the NAT gateways. | Charged depending on the number of NAT instances that you use, duration of usage, and instance type and size. |
| Type and size | Uniform offering; you don’t need to decide on the type or size. | Choose a suitable instance type and size, according to your predicted workload. |
| Public IP addresses | Choose the Elastic IP address to associate with a NAT gateway at creation. | Use an Elastic IP address or a public IP address with a NAT instance. You can change the public IP address at any time by associating a new Elastic IP address with the instance. |
| Private IP addresses | Automatically selected from the subnet’s IP address range when you create the gateway. | Assign a specific private IP address from the subnet’s IP address range when you launch the instance. |
| Security groups | Cannot be associated with a NAT gateway. You can associate security groups with your resources behind the NAT gateway to control inbound and outbound traffic. | Associate with your NAT instance and the resources behind your NAT instance to control inbound and outbound traffic. |
| Network ACLs | Use a network ACL to control the traffic to and from the subnet in which your NAT gateway resides. | Use a network ACL to control the traffic to and from the subnet in which your NAT instance resides. |
| Flow logs | Use flow logs to capture the traffic. | Use flow logs to capture the traffic. |
| Port forwarding | Not supported. | Manually customize the configuration to support port forwarding. |
| Bastion servers | Not supported. | Use as a bastion server. |
| Traffic metrics | Not supported. | View CloudWatch metrics. |
| Timeout behavior | When a connection times out, a NAT gateway returns an RST packet to any resources behind the NAT gateway that attempt to continue the connection (it does not send a FIN packet). | When a connection times out, a NAT instance sends a FIN packet to resources behind the NAT instance to close the connection. |
| IP fragmentation | Supports forwarding of IP fragmented packets for the UDP protocol. Does not support fragmentation for the TCP and ICMP protocols. Fragmented packets for these protocols will get dropped. | Supports reassembly of IP fragmented packets for the UDP, TCP, and ICMP protocols. |
Network ACL’s
- Your VPC automatically comes a default network ACL and by default it allows all outbound and inbound traffic.
- You can create a custom network ACL. By default, each custom network ACL denies all inbound and outbound traffic until you add rules.
- Each subnet in your VPC must be associated with a network ACL. If you don’t explicitly associate a subnet with a network ACL, the subnet is automatically associated with the default network ACL.
- You can associate a network ACL with multiple subnets; however, a subnet can be associated with only one network ACL at a time. When you associate a network ACL with a subnet, the previous association is removed.
- A network ACl contains a numbered list of rules that is evaluated in order, starting with the lowest numbered rule.
- A network ACl has separate inbound and outbound rules, and each rule can either allow or deny traffic.
- Network ACLs are stateless responses to allowed inbound traffic are subject to the rules for outbound traffic (and vice versa)
- Block IP Addresses using network ACL’s not Security Groups
Security Group vs Network ACL
| Security Group | Network ACL |
|---|---|
| operates at the instance level (first layer of defense) | Operates at the subnet level (second layer of defense) |
| Supports allow rules only | Supports allow rules and deny rules |
| Is stateful: Return traffic is automatically allowed, regardless of any rules | Is stateless: Return traffic must be explicitly allowed by rules |
| We evaluate all rules before deciding whether to allow traffic | We process rules in number order when deciding whether to allow traffic |
| Applies to an instance only if someone specifies the security group when launching the instance, or associates the security group with the instance later on | Automatically applies to all instances in the subnets it’s associated with (backup layer of defense, so you don’t have to rely on someone specifying the security group) |
NAT vs Bastions
- A NAT is used to provide internet traffic to EC2 instances in private subnets
- A Bastion is used to securely administer EC2 instance (using SSH or RDP) in private subnets. In Australia we call them jump boxes.
Resilient Architecture
- If you want resiliency, always have 2 public subnets and 2 private subnets. Make sure each subnet is in different availability zones.
- With ELB’s make sure they are in 2 public subnets in 2 different availability zones.
- With Bastion hosts, put them behind an autoscaling group with a minimum size of 2. Use Route53 (either round robin or using a health check) to automatically fail over.
- NAT instances are tricky to make resilient. You need 1 in each public subnet, each with their own public IP address, and you need to write a script to fail between the two. Instead where possible, use NAT gateways.
VPC Flow Logs
- You can monitor network traffic within your custom VPC’s using VPC Flow Logs.
VPC limit
- Currently you can create 200 subnets per VPC by default
Direct Connect
- What is Direct Connect https://aws.amazon.com/directconnect/?nc1=h_ls
- AWS Direct Connect makes it easy to establish a dedicated network connection from your premises to AWS. Using AWS Direct Connect, you can establish private connectivity between AWS and your datacenter, office, or colocation environment, which in many cases can reduce your network costs, increase bandwidth throughput, and provide a more consistent network experience than Internet-based connections.
- AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces. This allows you to use the same connection to access public resources such as objects stored in Amazon S3 using public IP address space, and private resources such as Amazon EC2 instances running within an Amazon Virtual Private Cloud (VPC) using private IP space, while maintaining network separation between the public and private environments. Virtual interfaces can be reconfigured at any time to meet your changing needs.
- Advantage of Direct Connect over VPN
- Bandwidth & a more consistent network experience!
- A VPC VPN Connection utilizes IPSec to establish encrypted network connectivity between your intranet and Amazon VPC over the Internet. VPN Connections can be configured in minutes and are a good solution if you have an immediate need, have low to modest bandwidth requirements, and can tolerate the inherent variability in Internet-based connectivity. AWS Direct Connect does not involve the Internet; instead, it uses dedicated, private network connections between your intranet and Amazon VPC.
- What is Direct Connect https://aws.amazon.com/directconnect/?nc1=h_ls
Network Bottlenecks
- Each Instance type have the ma bandwidth and throughput.
专项问题点
ELB Connection draining
- Min: 1s, Max: 3600, default: 300s
- helps the user to stop sending new requests traffic from the load balancer to the EC2 instance when the instance is being deregistered while continuing in-flight requests?
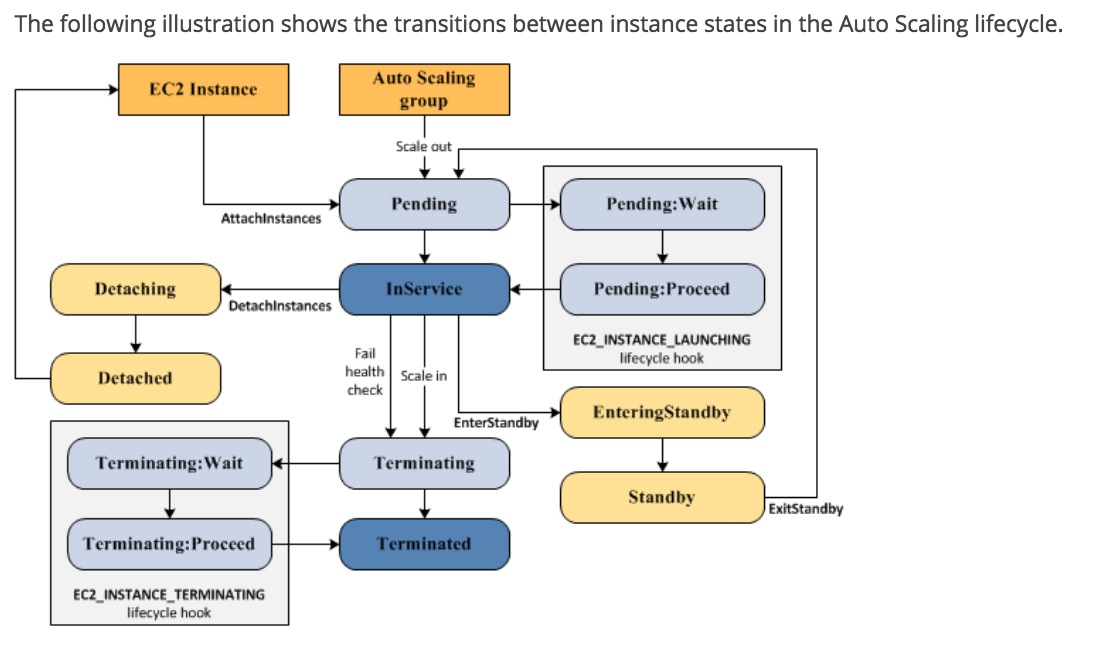
AutoScaling Group Lifecycle
CloudWatch 能监控的Metrics https://aws.amazon.com/cloudwatch/faqs/
- Amazon EC2 instances
- EBS volumes
- Elastic Load Balancers
- Auto Scaling groups
- EMR job flows
- RDS DB instances
- DynamoDB tables
- ElastiCache clusters
- RedShift clusters
- OpsWorks stacks
- Route 53 health checks
- SNS topics
- SQS queues
- SWF workflows
- and Storage Gateways
不提供Detail monitoring的service, 最细颗粒是5 mins的service
- EMR
- SNS
CloudWatch 免费detail monitoring的几个service https://aws.amazon.com/cloudwatch/details/?nc1=h_ls
- Auto Scaling groups: seven pre-selected metrics at one-minute frequency, optional and for no additional charge.
- Elastic Load Balancers: thirteen pre-selected metrics at one-minute frequency, for no additional charge.
- Amazon Route 53 health checks: One pre-selected metric at one-minute frequency, for no additional charge
- Amazon EBS PIOPS (SSD) volumes: ten pre-selected metrics at one-minute frequency, for no additional charge
- Amazon CloudFront: six pre-selected metrics at one-minute frequency, for no additional charge
- Amazon ElastiCache nodes: thirty-nine pre-selected metrics at one-minute frequency, for no additional charge.
- Amazon RDS DB instances: fourteen pre-selected metrics at one-minute frequency, for no additional charge.
- Amazon Redshift: Sixteen pre-selected metrics at one-minute frequency, for no additional charge
- AWS Opsworks: fifteen pre-selected metrics at one-minute frequency, for no additional charge.
- Amazon CloudWatch Logs: six pre-selected metrics at one-minute frequency, for no additional charge
CloudWatch 提供的几种统计值
- Average
- Minimum
- Maximum
- Sum
- Data Samples
- p99
- p95
- p90
- p50
- p10
CloudWatch AWS Namespaces
- There is no CloudTrail
- All Cloudwatch Namespaces
CloudWatch PutMetricData
- Each put-metric-data request is limited to 8KB in size for HTTP GET requests and is limited to 40 KB in size for HTTP POST requests.
SSL Negotiation Configurations for Classic Load Balancers
- Security Policies
- Predefined Security Policies
- Custom Security Policies
- SSL Protocols (no TLS 1.3)
- supported
- TLS 1.2
- TLS 1.1
- TLS 1.0
- SSL 3.0
- deprecated SSL Protocol
- SSL 2.0
- supported
- The Server Order Preference is not supported in the Security Policy ELBSecurity Policy-2011-08 security policy.
- Security Policies
ELB sticky session algorithm
- This is how the ELB algorithm works in general when Cookie is not present
- First it checks the cookie is present in the service request
- Since the cookie is not found in the request it will then decide which instance the service request should be routed to.
- Finally the cookie is inserted in the response
- This is how the ELB algorithm works in general when Cookie is present
- First it checks the cookie is present in the service request
- Since the cookie is found in the request it will then decide which instance the service request should be routed to based on the already present cookie.
- Finally the cookie is inserted in the response
- This is how the ELB algorithm works in general when Cookie is not present
ELB access log file format
- format: bucket[/prefix]/AWSLogs/aws-account-id/elasticloadbalancing/region/yyyy/mm/dd/aws-account-id_elasticloadbalancing_region_load-balancer-id_end-time_ip-address_random-string.log.gz
- sample: /AWSLogs/921187888888/elasticloadbalancing/us-west-2/2017/07/16/921187888888_elasticloadbalancing_us-west-2_awseb-e-u-AWSEBLoa-1KH856XXXXXXX_20170716T0000Z_35.161.113.177_1rhwm1ze.log
IAM user name rule
- User names can be a combination of up to 64 letters, digits, and these characters: plus (+), equal (=), comma (,), period (.), at sign (@), and hyphen (-). Names must be unique within an account. They are not distinguished by case
上传到CloudWatch的数据的时间戳
- past two week ~ two hours in the future : Each metric data point must be marked with a time stamp. The time stamp can be up to two weeks in the past and up to two hours into the future
根据Wizard创建 VPC with Public an Private Subnets时
- 默认会创建一个NAT Gateway,可以选择创建Nat Instance,并选择对应的Instance type和Key pair
- 创建两个Route Table
- 面向private子网,0.0.0.0/0指向Nat Instance的是Main Route Table
- 面向public,0.0.0.0/0指向Internet Gateway的是Custom Route Table
- 创建后不能直接删除,需要删除Public子网中的Nat Instance后才能删除VPC
ACL rule priority
- Rule number. Rules are evaluated starting with the lowest numbered rule. As soon as a rule matches traffic, it’s applied regardless of any higher-numbered rule that may contradict it.
VPC Dedicated Tenancy
- VPC 是非Dedicated的,建立EC2的时候是可以选Shared, Dedicated, Dedicated Host的
- VPC建立的时候就是建立的Dedicated VPC时,建立在此VPC中的EC2,是不能选Shared的,只有Dedicated和Dedicated Host
- 在启动实例后,要想更改其租赁属性,有一定限制。
- 在启动实例后,不能将其租赁属性从 default 改为 dedicated 或 host。
- 在启动实例后,不能将其租赁属性从 dedicated 或 host 改为 default。
- 在启动实例后,可以将其租赁属性从 dedicated 改为 host,或从 host 改为 dedicated
- You cannot change the tenancy of a default instance after you’ve launched it.
VPC Peering Limitations
- You cannot create a VPC peering connection between VPCs that have matching or overlapping IPv4 or IPv6 CIDR blocks. Amazon always assigns your VPC a unique IPv6 CIDR block. If your IPv6 CIDR blocks are unique but your IPv4 blocks are not, you cannot create the peering connection.
- You cannot create a VPC peering connection between VPCs in different regions.
- You have a limit on the number active and pending VPC peering connections that you can have per VPC.
- VPC peering does not support transitive peering relationships; in a VPC peering connection, your VPC does not have access to any other VPCs that the peer VPC may be peered with. This includes VPC peering connections that are established entirely within your own AWS account.
- You cannot have more than one VPC peering connection between the same two VPCs at the same time.
- A placement group can span peered VPCs; however, you do not get full-bisection bandwidth between instances in peered VPCs.
- Unicast reverse path forwarding in VPC peering connections is not supported.
- You can enable resources on either side of a VPC peering connection to communicate with each other over IPv6; however, IPv6 communication is not automatic. You must associate an IPv6 CIDR block with each VPC, enable the instances in the VPCs for IPv6 communication, and add routes to your route tables that route IPv6 traffic intended for the peer VPC to the VPC peering connection.
IAM Limitation
- Groups in an AWS account - 300
- Roles in an AWS account - 1000
- Customer managed policies in an AWS account - 1500
- Users in an AWS account - 5000
- Groups an IAM user can be a member of - 10
EC2 Termination Protection 不会保护来自instance内部的shutdown命令导致的terminal - http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/terminating-instances.html#Using_ChangingDisableAPITermination
- The DisableApiTermination attribute does not prevent you from terminating an instance by initiating shutdown from the instance (using an operating system command for system shutdown) when the InstanceInitiatedShutdownBehavior attribute is set.
CloudWatch can monitoring AutoScaling Metric
- 可以直接在CloudWatch中查看AutoScaling中EC2的整体指标,包括CPU,Network In/Out等
EBS limitation
- Number of EBS Volumes - 5000
- Number of EBS snapshots - 10000
VPC Limitation
- VPCs per region - 5
- Subnets per VPC - 100
Bucket Policy 优先级
- The explicited deny permission will override the allow
关于Redis中出现Eviction时的对应方法:
- 官网说是直接scale up by using a larger node type
- AcloudGuru上有讨论说处理方法是Only Scale out
- 各个