由于EC2中no space left引起的EB警报
问题现象
周末早上突然收到大量Elastic Beanstalk的警报邮件,提示一个跑Rails的EB环境中有大量的请求是HTTP 5xx。
登陆AWS Console查看相关Event,已经有持续的WARN提示有大量的HTTP 5xx请求。
解决过程
使用EB console下载了各个Instanc的日志,仔细进行排查。
最后在一个Instance的Rails log中发现有请求提示No space left on device。原来是Instance的磁盘满了,导致了部分需要写临时文件的请求失败了。
1 | F, [2018-08-11T02:10:43.084147 #11559] FATAL -- : |
初步调查
登陆出问题的Instance,df -h查看磁盘空间,发现磁盘上明明还有大量空间没使用。
1 | [ec2-user@ip-172-31-47-93 ~]$ df -h |
尝试touch文件, 失败,系统提示确实没有磁盘空间不足
1 | [ec2-user@ip-172-31-47-93 ~]$ touch 1 |
查看磁盘的inode节点,找到了问题,原来是磁盘的inode节点已经使用了100%。
1 | [ec2-user@ip-172-31-47-93 log]# df -i |
有磁盘空间,但是inode已经使用完毕了,说明系统中有大量的小文件存在, 极大可能是运行的Rails程序中的问题。
恢复服务
因为需要保留该Instance进行进一步的调查,所以不能简单的使用EB Console将有问题的EC2替换掉。
选择将有问题的Instance从ASG中Detach出来,这样既可以让服务恢复,又能保留存在问题的Instance进行详细调查。
进入AutoScaling的操作界面,找到EB使用的AutoScaling组,在AutoScaling组的Instances配置界面上输入问题Instance的ID,然后将该Instance Detach。
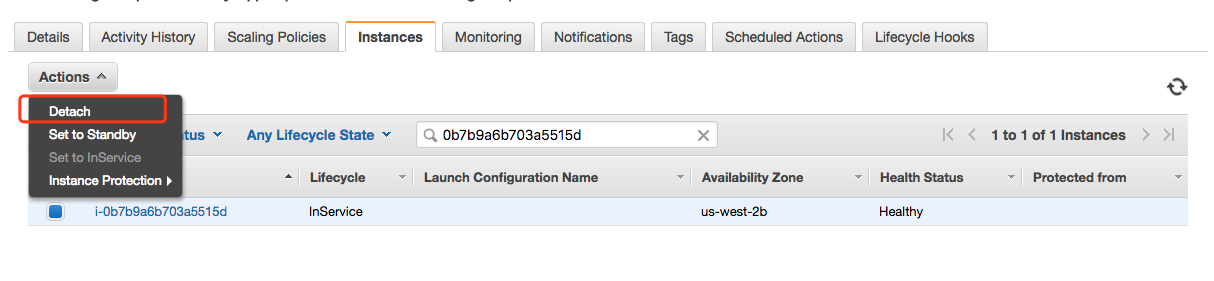
Detach后,EB自动检测到少了一台Instance,自动启了新的Instance,等新Instance启动完成后,EB服务恢复,不再有HTTP 5xx的WARN了。
深挖问题
服务恢复后,登陆有问题的Instance,使用命令find . -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -nr逐级查看各个目录中inode的使用量。
最终发现应用程序的/var/app/current/tmp目录消耗了巨大的inode。经过排查是某个固定的请求写了太多的缓存文件导致的问题。
总结
遇到只有某个Instance中才出现的问题时,可以选择将有问题的Instance隔离出EB环境,先恢复服务后再进行调查。
临时将EC2移出AutoScaling的两个方法:
- set to standby https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-enter-exit-standby.html
- 设置为standby后,排查完毕后还可以恢复入AutoScaling
- detach https://docs.aws.amazon.com/autoscaling/ec2/userguide/detach-instance-asg.html
- detach后,就脱离AutoScaling,不再占用desired capacity,AutoScaling会根据desired capacity再创建一个Instance来弥补