AWS RDS recovery due to issue with underlying hardware
早上刚上班就收到一封主题为”RDS Notification Message”的订阅邮件,message内容为”Recovery of the DB instance has started. Recovery time will vary with the amount of data to be recovered”。
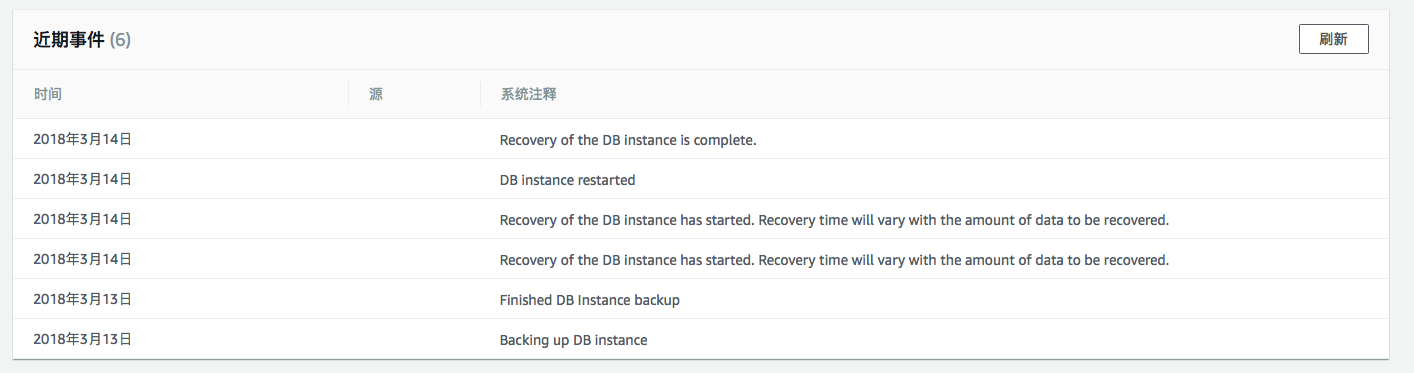
上Web Console查看发生了什么事,发现RDS已经自我恢复完毕了。最新的Event消息提示为”Recovery of the DB instance is complete.”
提了Case询问了下,也在网上搜了一下,基本搞清楚了是怎么个回事,记录如下。
原因
根据AWS 官方文档的描述,”Recovery of the DB instance has started. Recovery time will vary with the amount of data to be recovered.”的消息的RDS Event ID为RDS-EVENT-0020,属于RDS中recovery类别下。
但官方文档中没有提及,什么时候会导致发出这类Event。
经过调查,大致明白了出现这种消息,是因为承载了RDS Instance的底层硬件出问题,监控程序连接不上RDS Instance,就触发执行了recovery操作,应该算是RDS的一个自我恢复的机制。
像RDS这种PAAS服务,就能提供这种自我恢复的机制。而像EC2这种IAAS服务,当底层硬件down掉后,因为aws无法知道Instance里面运行了啥,所能做的就只能维护着现场的“尸体”,发送个通知给管理员,等管理员过来“收尸”了。不久前的”收尸”经历还历历在目。→_→ EC2底层硬件Retirement的处理方法。
解决办法
AWS针对这种情况的解决方案是建议是开启RDS的Multi-AZ功能, 开启Multi-AZ后,会启动一个备用RDS。主机和备用机之间使用同步复制技术,来保证数据的一致性。当主机出问题后,会转而使用备用机。切换是AWS自动进行的,RDS对外的Endpoint不会改变。唯一的影响就是原来连接到RDS主机的DB connect会中断,当client重连Endpoint的时候,就会连接到备用机上。
关于Multi-AZ的详细情况参见官网说明 –> High Availability (Multi-AZ)和Amazon RDS Multi-AZ Deployments
Multi-AZ的优点
简单罗列使用Multi-AZ的优点如下:
- 万一整个AZ都挂掉了,另一个AZ中还有一个同步的数据库可用
- Auto Backup的时候,在standby Instance上进行,不会造成primary Instance IO的下降和可能的短暂的不可用。
- RDS打patch的时候,不会有中断
- Primary Instance fail后,会自动切换为使用standby
Multi-AZ的缺点
唯一的缺点,那就是费用是Single-AZ的两倍,这个容易理解,因为实际上有两台Instance在运行。 PostgreSQL Multi-AZ的价格在此
总结
是机器就有可能会坏,无论是在自建的数据中心还是AWS的机房里面。绝大多数情况下,成熟云厂商的解决方案,都要比自己来运维要更靠谱。